
今日はプログラミングの基本の基本、一次元配列と二次元配列の違いを学んでいきましょうね。
「配列って何?」って思った人、心配いらないわ。
「配列とインデックの違い」で復習してみてね。
これから勉強していくんだから、一緒に頑張りましょう。
一次元配列とは、
データが一列に並んでいる配列
よ。
一次元配列は、まるで一本の線の上に並んだ箱のようなものね。

各箱が一つのデータを持っていて、同じ種類のデータを連続して保存できるの。
例えば、数を保存しておく箱がずらーっと並んでいるイメージよ。
この箱たちは、インデックスと呼ばれる番号を持っているのよ。
そして重要なのは、このインデックスは0から始まるってこと。
イメージを固めるために具体例を見てみましょう。
例えば、数学のテストの点数を保存するときに一次元配列を使えるわ。
点数を並べて保存して、あとで利用することができるわね。
今回は4つの点しかないけど、実際はもっと多くのデータも簡単に扱えるの。
次に、少しだけ進化した二次元配列について説明していくわよ。
二次元配列とは、
配列の中にさらに配列が入っている配列
よ。
二次元配列は、少し複雑になるけど心配しないで。
これは表のようなものだと思って。
縦と横に並んだデータを扱うことができて、それぞれのデータは行と列で決まるの。
例えば、席表を思い浮かべてみて。一列目の一番目、一列目の二番目……という感じで、データが配置されているの。

例えば、クラスのテストの点数表を考えてみましょう。
あるクラスの数学と英語の点数を保存する二次元配列があるとして、
| 数学 | 英語 |
|---|---|
| 80 | 85 |
| 90 | 95 |
というふうに、一人ひとりの点数をしっかり整理できるわ。
各生徒のインデックスは[行番号][列番号]で表されるのよ。
さて、一次元配列と二次元配列の違いをまとめてみましょう。
一次元配列は、直線上にデータを並べるシンプルなもの。
それに対して、二次元配列は、縦と横にデータを配置できるので、表現の幅が広いの。
この2つの違いを理解することで、プログラミングの基礎力は飛躍的にアップするわよ。
それじゃあね!
配列とインデックスが明らかに区別できると、プログラマーとして一歩前進できると思わない?
配列もインデックスも、データを扱う上で重要な概念だからしっかり理解する必要があるのよ。
配列とは、
データを整然と並べたもの
よ。
その役割をしっかり理解していきましょう。
配列の役割はとってもシンプルで、同じ種類のデータをまとめて置く場所なの。
友達の連絡先を一つのノートにまとめるイメージね。

たとえば、数値のデータを扱うプログラムで、複数の数を一緒に処理したいときに活躍するわ。
配列があると、複数の変数を使わずに、一つのまとまったデータとして扱えるというわけ。
配列は通常、データのリストを連続したメモリの位置に格納するの。
だから順番にデータを取り出すことができるのよ。
プログラミング言語によっては配列の中に入るデータの数、つまり「長さ」が決まっていることが多いわ。
この辺りは覚えておくとプログラミングの時に楽になるわね。
次にインデックスについて説明するわ。
インデックスとは、
配列の中のデータがどこにあるかを指し示すもの
よ。
人間で言えば名前を使ってその人を識別するようなものね。
プログラム内では、配列の最初の場所を「0」として、その後は「1」、「2」、と続いていくわ。
だからインデックスは配列内の位置とも言えるわね。
例えば、友達リストを考えてみて。
リストが「タカシ、ユウコ、ジャック」だとすると、タカシはインデックス0、ユウコはインデックス1、ジャックはインデックス2でアクセスできるわ。
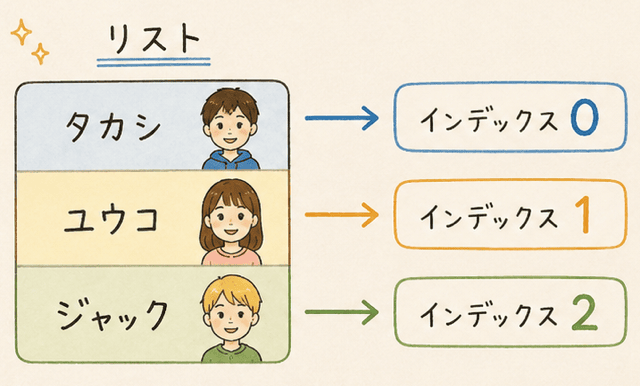
このようにインデックスがあれば、配列内の特定のデータに素早くアクセスできるの。
さて、強調してきた配列とインデックスの違いを見てみましょう。
基本的なところを押さえておくと混乱しにくいわ。
それぞれの役割をしっかり認識すれば、多くのデータを効率的に扱えるようになるのよ。
配置されているデータの「棚」が配列、その棚の「ラベル」がインデックスみたいなものね。

このイメージを持つと、理解が進むと思うわ。それぞれ違うことをしているけど、一緒に使うと効果的って感じかな。
プログラミングを理解する上で避けて通れないのが順次構造、選択構造、反復構造の3つの基本構造よ。
これらはすべて、
プログラムの命令の進み方を表す型
なの。
これを押さえれば、プログラムの流れを把握するのがぐっと楽になるの。
順次構造とは、
プログラムの中で命令を上から順番に実行していく型
よ。
考えてみて。
日常の活動も、例えば朝起きてから夜寝るまでの流れは、順番に沿って進んでいるわよね。
たとえば、わたしの朝の1日の始まりはこんな感じ。
これは全部順次構造ね。
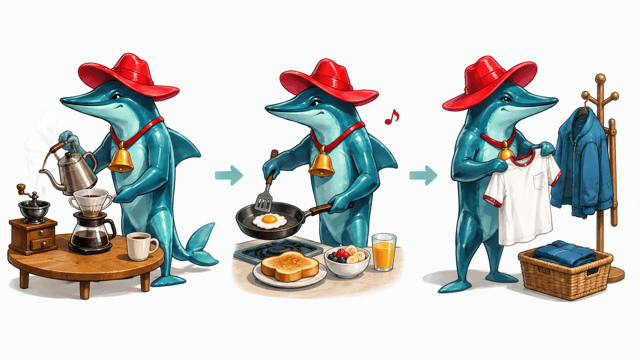
このように、行動が順番に並ぶときに使われるわ。
次に選択構造とは、
条件に基づいて処理を分岐させる型
よ。
もし〜なら、〜する
というように判断する時に使われるの。
みんなも日常的に選択していることが多いのよ。
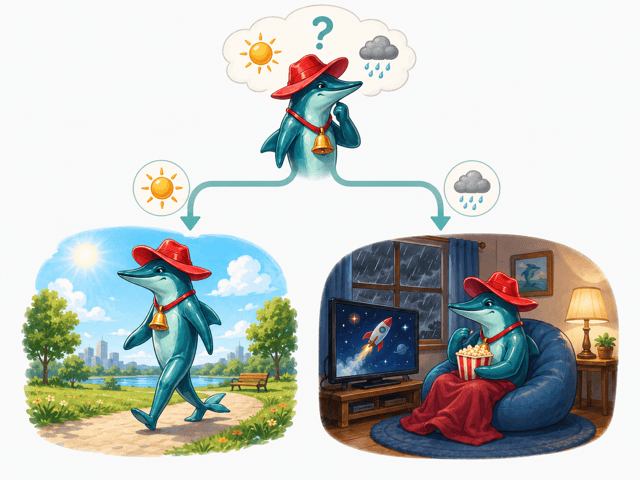
こんな風に、判断内容によって進む道を変えるのが選択構造ね。
反復構造とは、
同じ処理を何度も繰り返す型
よ。
日常の作業でもよくやっているわよね。
例えばこんなこともあるでしょう。
このように、繰り返したい処理があるときは反復構造がお役に立つのよ。
また次回、一緒に新たなプログラミングの世界を探検しましょう。
それじゃあね!
今日はプログラミングの世界でよく出会う構文エラー、実行時エラー、そして論理エラーの違いについておしゃべりするわよ。
それぞれのエラーの性質を理解することで、プログラム作成がもっとスムーズになるはずよ!
構文エラーとは、
プログラムをコンピュータが読み込む際に生じる文法上のミス
よ。
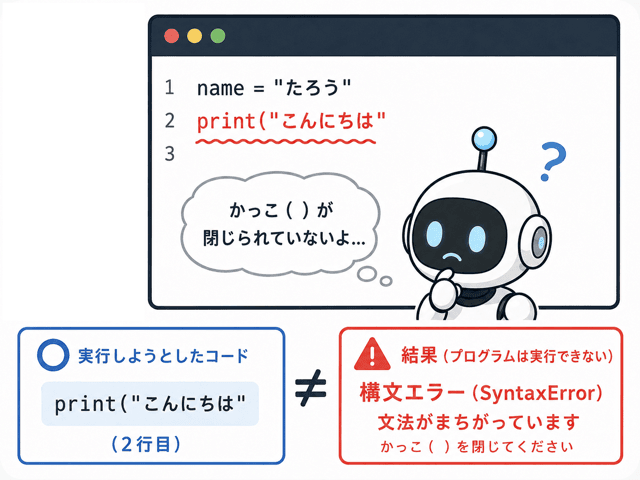
これによって、プログラムが機械語に変換されないのよ。
例えば、文末にセミコロンを忘れたらもう大変!
プログラム言語はみんな規則があるから、それを守らないと怒っちゃうの。
エディタが賢いから、間違いを教えてくれるわよ。だから見落としてもすぐに直せるの。
実行時エラーとは、
プログラムを実際に動かしている間に発生するエラー
よ。

つまり、プログラムが途中で止まっちゃうことね。
ゼロで割ったり、存在しないファイルにアクセスしようとしたりするとこうなるわ。
この場合、コンピュータがエラーメッセージをくれるから、比較的解決もしやすいわよ。
論理エラーとは、
プログラムが一応動くけど、結果がおかしい時に起こるエラー
よ。

一番ややこしいエラーね。
エラーメッセージも出してくれないから、自分でプログラムを見直すしかないの。
例えば計算式が間違っていた場合、数字は出るけど間違った結果になるってこと。
この記事を通じて、あなたもエラーの違いを理解しながら、もう一歩プログラミングに近づけたはずよ!
それじゃあ!
今日は「バグ」と「デバッグ」についてお話ししていくわね。
これ、コンピューターの世界ではよく出てくる言葉なんだけど、ちゃんと理解しているかって言われるとちょっと不安よね。
バグっていうのは、簡単に言うと「プログラムのミスや不具合」のことよ。

コンピューターにおいて、期待通りの結果を出せない原因がこのバグであることが多いの。
バグがあると、プログラムがうまく動かないのよね。
バグにはいろいろな種類があるわ。例えば、
文章を書くのと同じように、プログラミングにも誤字脱字のようなミスがあるのね。
さて、次にデバッグについてお話しするわね。
これは、
バグを探して取り除く作業よ。

プログラムには、作った人でも見落としてしまうようなミスが潜んでいるかもしれないわね。
そこでデバッグが重要なの。
デバッグにはいくつかの方法があるわ。基本的には以下のような手順を参考にしてね。
デバッグは、問題を見つけるだけじゃなく、その根本原因を理解するためにも大切なプロセスよ。
最後にバグとデバッグの違いをしっかり理解しておきましょう。
ズバリ、
バグは「問題点そのもの」で、デバッグは「その問題を取り除く作業」なのよ。
この違いをしっかりと押さえておくことが大事ね。
ゴミ拾いで考えると分かりやすいわ。
きれいな公園に、空き缶が1つ落ちていたとするわね。

この空き缶が、プログラムでいうバグみたいなものなの。
つまり、
本来そこにあってはいけないもの
全体を乱している問題点
がバグなのよ。
一方で、デバッグは、その空き缶を見つけて拾い、ゴミ箱に捨てる作業にあたるわ。

どこにゴミが落ちているか探す
空き缶を見つける
拾って取り除く
公園をきれいな状態に戻す
この流れが、デバッグのイメージね。
プログラムでも同じように、
どこに不具合があるか探す
原因を見つける
コードを修正する
正しく動く状態に戻す
という作業をするの。
つまり、ゴミ拾いでたとえるなら、
バグは、公園に落ちている空き缶。
デバッグは、その空き缶を見つけて拾い、きれいにする作業。
ということね。
プログラミング言語と機械語の違い、読者のみんなと一緒に探検してみましょう。
まず最初に知っておきたいのがプログラミング言語のこと。
これは、
コンピュータに仕事を頼むための言語
よ。

コンピュータは私たちの言葉を聞いても理解できないけど、この言語を使えば、コンピュータが正確に指示を理解できるの。
例えば、Pythonで書いた掃除のプログラムならこんな感じ。
def prepare_cleaning_tools():
print(“掃除道具を用意する”)def throw_away_trash():
print(“ゴミを捨てる”)def tidy_up_room():
print(“散らかった物を片付ける”)def vacuum_floor():
print(“掃除機をかける”)def wipe_desk():
print(“机を拭く”)def finish_cleaning():
print(“掃除完了!部屋がきれいになりました”)# プログラムを実行する
prepare_cleaning_tools()
throw_away_trash()
tidy_up_room()
vacuum_floor()
wipe_desk()
finish_cleaning()
このプログラミング言語にはたくさんの種類があるの。
そして、それぞれの言語には得意なことや特徴があるわ。
例えば、Pythonなんかはシンプルな書き方とたくさんのライブラリを持っているから、統計や人工知能の分野でたくさん使われているのよ。
以下の表にまとめたらから参考にしてみて。
| 種類 | 特徴 | 代表的な言語 | よく使われる場面 |
|---|---|---|---|
| 手続き型言語 | 処理を順番に書いていく言語 | C、Pascal | OS、組み込みシステム、基本的なプログラム |
| オブジェクト指向言語 | データと処理を「オブジェクト」としてまとめて扱う言語 | Java、C++、C#、Ruby | 大規模システム、アプリ開発、ゲーム開発 |
| スクリプト言語 | 比較的短く書けて、手軽に実行しやすい言語 | Python、JavaScript、PHP、Ruby | Web開発、自動化、データ処理 |
| 関数型言語 | 関数を組み合わせて処理を作る言語 | Haskell、Lisp、Scala、F# | 数学的な処理、並行処理、研究分野 |
| マークアップ言語 | 文章や画面の構造を表す言語 | HTML、XML | Webページ、データ構造の表現 |
| スタイルシート言語 | 見た目やデザインを指定する言語 | CSS | Webページのデザイン |
| データベース言語 | データベースを操作するための言語 | SQL | データ検索、追加、更新、削除 |
| 低水準言語 | コンピュータの機械に近い命令を書く言語 | アセンブリ言語 | ハードウェア制御、組み込み開発 |
次は機械語について。
これは、
コンピュータのCPUが直接理解できる言葉
ね。
コンピュータって、0と1のビットで命令を実行するのを知ってる?
だからつまり機械語は0と1の羅列ってことよ。
イメージ的には、
10110000 01100001
01001000 10010000
こんな感じ。
この言葉は、超シンプルだけど超重要。
私たちが何かを読む時って日本語とか英語を使うけれど、コンピュータは機械語を使ってるのよ。
だって、これがないとコンピュータは動けないのね。
プログラミング言語と機械語の違いは、ズバリ、
誰のために作られた言葉か
の違いよ。
プログラミング言語は、人間がコンピュータに命令を書きやすくするための言葉なの。
たとえば、PythonやJavaScriptのような言語では、
画面に文字を表示する
計算する
データを保存する
といった命令を、人間が比較的読みやすい形で書けるわ。
一方で、機械語は、コンピュータが直接理解するための言葉よ。
コンピュータのCPUは、最終的には0と1の組み合わせで命令を処理しているの。
つまり、
プログラミング言語は人間のための言葉。
機械語はコンピュータのための言葉。
ということね。

ただし、人間が書いたプログラミング言語は、そのままではコンピュータが直接理解できないことが多いわ。
だから、コンパイラやインタプリタと呼ばれる仕組みを使って、プログラミング言語を機械語に変換するのよ。
流れとしては、こんな感じね。
人間がプログラミング言語で書く
↓
コンパイラやインタプリタが変換する
↓
機械語になる
↓
コンピュータが実行する
それじゃあね!
今日は、アルゴリズムとプログラムの違いについて学んでいくわね。
これを理解することで、コンピューターがどのように問題を解決しているのかが分かるはずよ。
まずは、アルゴリズムとプログラムの基本から見ていきましょう。
アルゴリズムとは、
問題解決のための手順や方法を示したもの
よ。
例えば、数字の並びを小さい順に並べ替えるにはどうすればいいのか、という問題を解くための手順を示したものがアルゴリズムよ。
そう、アルゴリズムは「何を」、「どのような順番で」、「何に対して行うのか」を記述したもので、問題解決の手続きを一般化しているのね。
また、アルゴリズムを視覚的に分かりやすく表現した図にフローチャートなどがあるわ。
プログラムとは、
アルゴリズムをコンピュータ上で実行できるように、コンピュータに命令を指示する言語で表したもの
よ。
アルゴリズムが「料理のレシピ」だとしたら、プログラムはそのレシピに基づいて料理を作る「料理人の手順書」なの。
このプログラムを作成することをプログラミングと言うのよ。
つまり、プログラムはアルゴリズムが動けるようにコンピュータに伝えるための表現方法、って感じね。
さて、それではもっと分かりやすくするためにアルゴリズムとプログラムの違いの具体例を見てみましょう。
例えば、美味しいパスタを作るアルゴリズムを考えてみよう。
このように手順通りに進めれば、美味しいパスタが作れるのよ。
では、次にこのアルゴリズムをコンピュータで実行するプログラムを考えてみましょう。
これは簡単に言えば、パスタロボットを動かすための指令書ね。
例えば、
supply_ingredients();boil_pasta();make_sauce();mix_pasta_and_sauce();plate_pasta();コンピュータはこれを実行することで、美味しいパスタを作れるわけ。
では、それじゃあね!
データは、ざっくり「量的データ」と「質的データ」に分けられていて、それぞれの性質に基づいて4つの尺度があるわ。
この尺度について詳しく解説していくわね。
これらは質的データに分類されるわよ。
名義尺度は、分類として意味を持つ分類を表すのに使われる尺度ね。
例えば、性別や血液型、好きな食べ物などがそう。

数値としての意味は全くなく、異なるグループを区別するためのものなの。
だから、数学的な演算はできないわ。
順序尺度は、順序に意味がある分類を示すのに使われるの。
例えば、5段階の成績評価や服のサイズ(S, M, L, LLなど)ね。
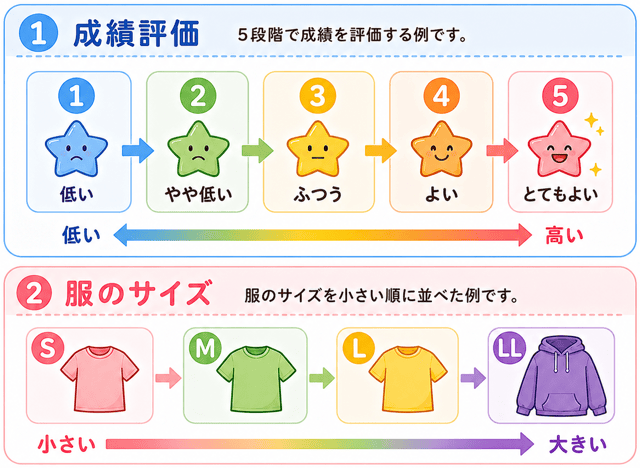
ただ、重要なのは、間隔が一定でないということ。
SサイズとLサイズの平均がMサイズになるわけじゃなくて、加減乗除の計算も意味をなさないのよ。
こちらは量的データとして計算ができるわ。
間隔尺度は、数値の間隔や差が意味を持つ尺度よ。
例えば、西暦や気温がこれに当たるわね。
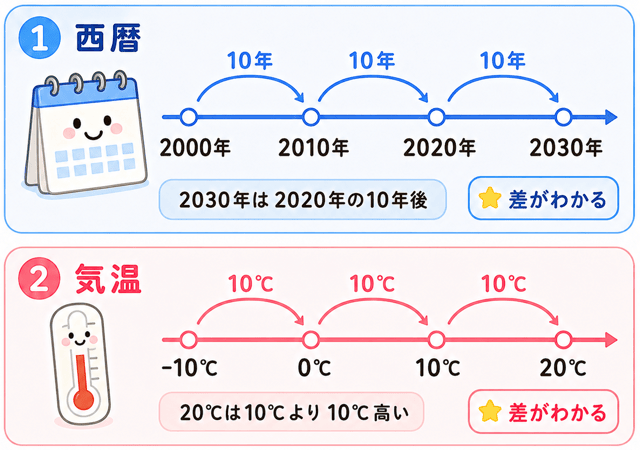
西暦2030年は2020年から10年後と表せるし、その平均値も計算できるわ。
だけど、20℃は−10℃の何倍かなんて計算は意味をなさないの。
比例尺度は、比にも意味がある尺度なの。
例えば、長さがそうね。
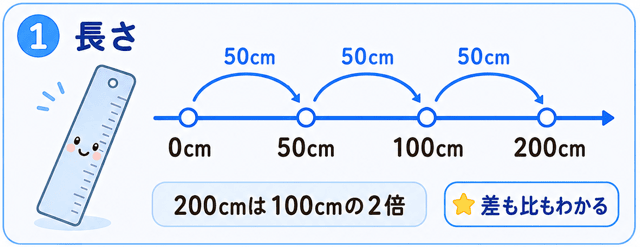
「長さが1000mなら、500mの2倍」というように、比の計算が意味を持つデータなのよ。
えっ、尺度の違いがこんがらがるですって??
そうね、覚え方を伝授しておくわ。
名義尺度の覚え方はズバリ、
母の名義で、アンケートの「性別・血液型・好きな食べ物」を答える
よ。

母の名義でアンケートを書いている男の子が、
お母さんの血液型って何だっけ……?
好きな食べ物って何だったっけ……?
と、気まずそうに悩みながら回答しているシーンを想像してみて。
ここで答えている、
は、どれも種類を表すデータなの。
たとえば、
のように、グループに分けるためのデータね。
ただし、これらには順番や大小はないわ。
A型がB型より大きいとか、寿司がラーメンより上とか、そういう意味はないの。
だから名義尺度は、
名前をつけて分類するだけのデータ
と考えると分かりやすいわ。
順序尺度の覚え方は、
順序よく服のサイズを試しているシーン
を想像すると分かりやすいわ。
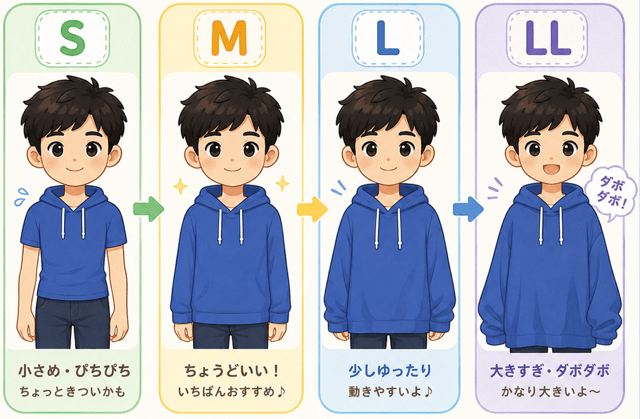
S、M、L、LLの服を、順番に試着していくの。
Sは小さい。
Mはその次。
Lはさらに大きい。
LLはもっと大きい。
つまり、服のサイズには、
S → M → L → LL
という順序があるのね。
ただし、ここで大事なのは、サイズに順番はあっても、
SとMの差
MとLの差
LとLLの差
が、必ず同じとは限らないということよ。
だから順序尺度は、
順番は分かるけれど、差の大きさまでは正確には分からないデータ
なの。
間隔尺度の覚え方は、
理科の実験で使う温度計の目盛りの間隔
をイメージすると分かりやすいわ。

温度計を見ると、0℃、10℃、20℃、30℃のように、目盛りが同じ間隔で並んでいるでしょう?
10℃から20℃の差は10℃。
20℃から30℃の差も10℃。
このように、間隔尺度では、
差に意味がある
の。
西暦も同じね。
2020年から2030年は10年後。
2000年から2010年も10年後。
このように、年と年の差を考えることができるわ。
ただし、間隔尺度では何倍かを考えるのは苦手なの。
たとえば、
20℃は10℃の2倍暑い
とは言わないわよね。
0℃は「温度がまったくない」という意味ではないからなの。
だから間隔尺度は、
差は分かるけれど、比は考えにくいデータ
と覚えるといいわ。
比例尺度の覚え方は、
男の子の身長が、比例グラフのように年々大きくなっていく様子
を想像すると分かりやすいわ。
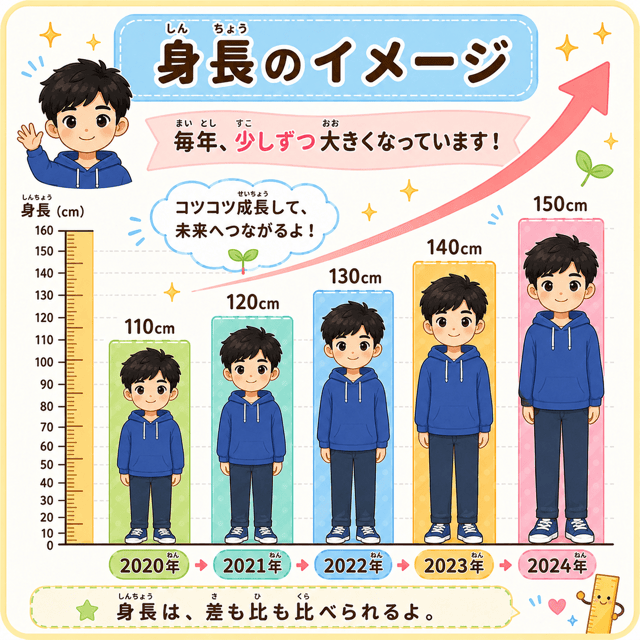
たとえば、身長が110cm、120cm、130cm、140cmと伸びていくとするわね。
この場合、
120cmは110cmより10cm高い
140cmは120cmより20cm高い
のように、差を比べることができるわ。
さらに、比例尺度では、
何倍か
も考えることができるの。
たとえば、
200cmは100cmの2倍
という言い方ができるわね。
これは、身長の0cmが「長さがまったくない」という意味を持っているからなの。
つまり、比例尺度では0が本当のゼロを表すのよ。
身長のほかにも、
などは比例尺度にあたるわ。
比例尺度は、
差も分かるし、比も分かるデータ
なの。
最後に、4つの尺度の覚え方をまとめておくわ。
| 尺度 | 覚え方 | ポイント |
|---|---|---|
| 名義尺度 | 母の名義でアンケートに答える | 種類を答えるだけ |
| 順序尺度 | 順序よく服のサイズを試す | 順番がある |
| 間隔尺度 | 温度計の目盛りの間隔を見る | 差に意味がある |
| 比例尺度 | 身長がグラフのように伸びる | 差も比も分かる |
つまり、
名義尺度は、種類。
順序尺度は、順番。
間隔尺度は、差。
比例尺度は、差と比。
と覚えると分かりやすいわ。
それじゃあ、始めましょうか。二つのデータタイプで混乱したことがある人、いるかしら?ここで解消していきましょう!
質的データとは、一言でいえば「性質や特徴を表すデータ」のことよ。
質的データの理解に役立つ例をいくつか挙げるわね。
血液型や髪の色みたいな例では、数値で表せない情報が該当するの。

質的データはアンケートやマーケティング調査などでよく使われるの。このデータを使うと、消費者の嗜好やトレンドを追いかけることができるのよ。
量的データは、「数量を表すデータ」のことなの。
数値で表現できるデータだから、あたしも計算がしやすいのは嬉しいわ。
ここでは量的データの具体例を見ていきましょう。
これらは数値で表せるからこそ、いろんな計算や分析が可能になるのよ。
量的データは、統計解析やデータ分析において非常に重要よ。平均や分散を計算したり、グラフにしたりするのに使用されるわ。
さて、質的データと量的データの違いをズバリ言っちゃうわよ。
この2つの違いは、
データが表しているもの
が違うのね。
質的データは、種類や分類を表すデータ。
一方で、量的データは、数値の大きさや量を表すデータなの。
質的データは、ものごとの種類・分類・属性を表すデータよ。
たとえば、
などが質的データにあたるわ。
これらは、
どの種類か
どのグループに入るか
を表しているの。
たとえば、血液型ならA型、B型、AB型、O型のように分類できるわね。
髪の色なら、黒、茶、金、赤などに分けられるわ。
ただし、質的データは基本的に、数値として足し算したり平均を出したりするものではないの。
血液型の平均を出す、というのは変でしょう?
だから質的データは、主に分類するために使われるのよ。
一方で、量的データは、数値の大きさや量を表すデータよ。
たとえば、
などが量的データにあたるわ。
これらは、
どれくらいか
どのくらい大きいか
どのくらい重いか
どのくらい多いか
を表しているの。
たとえば、身長なら150cm、170cm、180cmのように数値で表せるわね。
体重なら50kg、60kg、70kgのように、量の大小を比べることができるわ。
量的データは数値として扱えるから、平均を出したり、差を計算したり、グラフにしたりしやすいの。
質的データと量的データは、処理方法も違うわ。
質的データは、主に分類・集計に使うの。
たとえば、
A型の人は何人いるか
黒髪の人は何人いるか
春が好きな人は何人いるか
のように、カテゴリごとの人数や割合を見るのに向いているわ。
一方で、量的データは、主に計算・比較・グラフ化に使うの。
たとえば、
平均身長を出す
最高点と最低点の差を出す
体重の変化を折れ線グラフにする
といった処理ができるわ。
| 項目 | 質的データ | 量的データ |
|---|---|---|
| 表すもの | 種類・分類・属性 | 数値の大きさ・量 |
| 問い方 | 何の種類? | どれくらい? |
| 例 | 血液型、髪の色、好きな季節 | 年齢、身長、体重 |
| 主な使い方 | 分類・集計 | 計算・比較・グラフ化 |
| 平均 | 基本的に出せない | 出せる |
最後に、それぞれのデータタイプをもう一度整理しておきましょう。
質的データ
血液型、髪の色、好きな季節、性別、居住地域
量的データ
年齢、身長、体重、点数、気温、売上金額
まとめると、
質的データは「種類」を表すデータ。
量的データは「量」を表すデータ。
ということね。
観測や実験、調査を行うとき、得られる測定値と実際の真の値とのズレを経験するものよ。
このズレを私たち、データの世界では
誤差
と呼ぶわ。
たとえば、使用する機器の精度や操作の熟練度によって、この誤差が生まれるの。
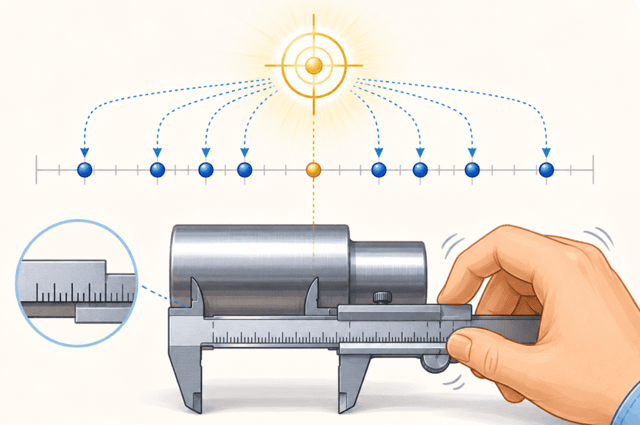
測定値のばらつきが小さいほど、データは精密、つまり精度が高いとされるのよ。
また、環境や装置の構造的理由で測定値にズレが生じることがあるけど、これは正確さに影響しているの。
この場合、測定値の平均が真の値に近ければ近いほど、測定は正確だといえるわね。
時として、一部の測定値が他と大きく異なる場合があるの。
それを
外れ値
って呼んでいるわ。
単なるミスで生まれることもあれば、とても特別な条件で現れることもあるのよ。
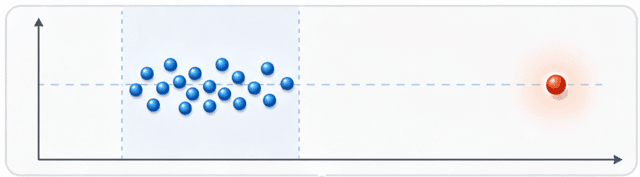
たとえば、観測中に誰かが機器を触っちゃったとか、雷などの自然現象による一時的な影響で測定値がズレることが考えられるの。
だから、外れ値が見つかったら、実験をもう一度して確認することが大事なのよ。
データ収集のときに、何らかの理由でデータが取得できなかった場合、それを欠損値と呼ぶのよ。
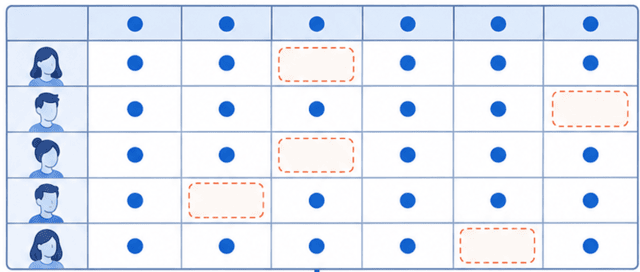
たとえば、アンケートでの記入漏れや、実験機器の故障などが原因として考えられるわ。
アンケートの場合、曖昧な質問や答えたくない質問があると欠損につながるの。だから、質問の設計は工夫が必要ね。
最後に誤差・外れ値・欠損値の違いを表でまとめておくわ。
| 用語 | 意味 | イメージ |
|---|---|---|
| 誤差 | 本当の値と、測定した値とのズレ | 少しだけズレている |
| 外れ値 | 他のデータと比べて、極端に大きい・小さい値 | ひとつだけ目立って離れている |
| 欠損値 | 本来あるはずなのに、データが入っていない値 | 空欄・未入力になっている |
それじゃあね!
データマイニングとは、
大量のデータセットから重要なパターンを探し出す技術
よ。

データマイニングの目的は、データから意味のあるパターンや法則を見つけ出すこと。
これにより、企業は新たなビジネス機会を見つけたり、プロセスの改善点を特定したりすることができるわ。
主に数値データやグラフを使うのがデータマイニングの特徴ね。
クロス集計という手法で、異なるデータの関係性を分析したりもするの。
テキストマイニングとは、
文章データを対象にしたデータマイニングの一種
よ。

文章を単語や文節単位に分解し、出現回数や傾向を解析することで文章の特性を抽出するの。
SNSのテキストデータを解析して企業が商品イメージを分析したり、アンケートの自由記述回答を解析して傾向を把握したりするのに役立つの。
さて、いよいよ本題に入るわよ。
ズバリ、データマイニングとテキストマイニングの違いは、
用語の範囲の違いね。
データマイニングは、数値データ、売上データ、購入履歴、アクセスログ、アンケート結果など、さまざまなデータを対象にする広い言葉なの。
一方で、テキストマイニングは、その中でも文章データを対象にした分析のことよ。
つまり、関係としては、
テキストマイニングはデータマイニングの一種
と考えると分かりやすいわ。
この関係は、そう、
家電と掃除機の関係ね。

掃除機は家電の一種。
でも、家電すべてが掃除機というわけではないわ。
冷蔵庫、洗濯機、電子レンジ、エアコン、テレビなど、家電にはいろいろな種類があるでしょう?
それと同じで、テキストマイニングはデータマイニングの一種なの。
でも、データマイニングすべてがテキストマイニングというわけではないのよ。
データマイニングには、文章データだけでなく、
など、さまざまなデータの分析が含まれるわ。
一方で、テキストマイニングが対象にするのは、
といった文章データなの。
つまり、
テキストマイニングはデータマイニングである。
しかし、データマイニングは必ずしもテキストマイニングではない。
という関係ね。
| 項目 | データマイニング | テキストマイニング |
|---|---|---|
| 対象 | 数値、表、履歴、ログなど幅広いデータ | 文章データ |
| 具体例 | 売上データ、購入履歴、アクセスログ | 口コミ、レビュー、SNS投稿、自由記述 |
| 見つけるもの | 法則、傾向、関連性、パターン | よく使われる言葉、話題、感情、意見の傾向 |
| イメージ | データの山から価値ある情報を掘り出す | 文章の山から価値ある情報を掘り出す |
| 関係 | 広い概念 | データマイニングの一種 |
みんなもデータの世界に飛び込んで、いろんな発見をしてみてね。
それじゃあ!
デジタル社会では、メール、電子契約書、ソフトウェア、Webサイトの証明書など、いろいろなデータがインターネット上でやり取りされているわ。
でも、ここで不安になるのが、
このデータ、本当に本人が送ったものなの?
途中で誰かに書き換えられていないの?
ということよね。
そこで活躍するのが、
デジタル署名
なの。
デジタル署名とは、簡単にいうと、
このデータは本人が作ったものです
途中で改ざんされていません
ということを確認するための仕組みよ。

紙の世界でいうと、印鑑やサインに近いわね。
ただし、デジタル署名はただ名前を書くわけではないの。暗号技術を使って、本人確認と改ざん検出を行う仕組みなのよ。
デジタル署名で確認できることは、大きく分けて2つあるわ。
| 確認できること | 意味 |
|---|---|
| 本人性 | 本当にその人・組織が作ったデータなのかを確認できる |
| 完全性 | 途中でデータが改ざんされていないかを確認できる |
例えば、Aさんが電子契約書にデジタル署名をしたとするわ。
その場合、受け取った人は、
この契約書は本当にAさんが署名したものか?
署名されたあとに内容が書き換えられていないか?
を確認できるの。

つまりデジタル署名は、デジタル世界の「本人のしるし」と「改ざんチェック」を兼ねた仕組みなのよ。
デジタル署名の仕組みを理解するためには、まず公開鍵暗号方式を押さえておく必要があるわ。
公開鍵暗号方式では、2つの鍵を使うの。
デジタル署名では、この2つの鍵を次のように使うのよ。
秘密鍵で署名する
公開鍵で検証する
ここがとても大事なところね。
まず、送信者は自分の秘密鍵を使ってデータに署名するわ。
秘密鍵は、本人だけが持っている鍵よ。
だから、その秘密鍵で作られた署名は、
これは本人が作った署名だと考えられる
という証拠になるの。
紙の世界でいうと、本人しか持っていない印鑑で押印するようなイメージね。
受信者は、送信者の公開鍵を使って、その署名が正しいかを確認するわ。
公開鍵は、名前の通り公開してよい鍵よ。
そのため、受信者は公開鍵を使って、
この署名は本当に送信者の秘密鍵で作られたものか?
データは途中で改ざんされていないか?
を確認できるの。
では、デジタル署名の流れをもう少し具体的に見ていきましょう。
まず、送信者は送りたいデータからハッシュ値を作るわ。
ハッシュ値とは、データを短くまとめた要約データのようなものよ。
例えば、長い文章やファイルをそのまま署名するのではなく、まずそのデータから短い要約を作るの。
この要約がハッシュ値ね。
次に、そのハッシュ値を送信者の秘密鍵で処理するわ。
これによって作られるのが、デジタル署名なの。
つまり、デジタル署名はざっくりいうと、
データのハッシュ値を、送信者の秘密鍵で署名したもの
と考えると分かりやすいわ。
送信者は、元のデータとデジタル署名を一緒に送るわ。
受信者はそれを受け取って、署名が正しいか確認するの。
受信者は、送信者の公開鍵を使ってデジタル署名を確認するわ。
さらに、受け取ったデータから自分でもハッシュ値を作るの。
そして、
署名から確認したハッシュ値
受け取ったデータから作ったハッシュ値
この2つを比べるのよ。
もし2つのハッシュ値が一致すれば、
データは途中で改ざんされていない
署名は送信者の秘密鍵で作られたものだと確認できる
ということになるわ。
逆に、少しでもデータが書き換えられていると、ハッシュ値が変わってしまうの。
だから、署名の確認に失敗するのよ。
ここで出てきたハッシュ値について、もう少し説明するわね。
ハッシュ値とは、元のデータから作られる短い文字列のことよ。
データの「指紋」のようなものだと考えると分かりやすいわ。
ハッシュ値には、次のような特徴があるの。
例えば、文章の中の1文字だけを変えたとしても、ハッシュ値は別のものになるわ。
だから、受信者はハッシュ値を比べることで、
このデータは途中で変えられていないか?
を確認できるの。
ここで注意したいのが、デジタル署名と暗号化は目的が違うということよ。
どちらも暗号技術を使うけれど、役割は同じではないの。
| 項目 | 目的 | 主に使うもの |
|---|---|---|
| 暗号化 | 内容を読めないようにする | 相手の公開鍵や共通鍵など |
| デジタル署名 | 本人性と改ざんなしを確認する | 送信者の秘密鍵 |
暗号化は、
中身を隠すための仕組み
よ。
一方、デジタル署名は、
誰が作ったのか、途中で変えられていないかを確認する仕組み
なの。
つまり、デジタル署名をしたからといって、必ずしも中身が隠れるわけではないのよ。
ここは間違えやすいところね。
デジタル署名では、公開鍵を使って署名を確認するわ。
でも、ここで1つ問題があるの。
それは、
その公開鍵は、本当に本人の公開鍵なの?
という問題よ。
もし悪い人が、
これがAさんの公開鍵です
と言って、偽物の公開鍵を配っていたらどうなるかしら?
受信者はその偽物の公開鍵を信じてしまうかもしれないわ。
これでは、なりすましを防げないの。
そこで必要になるのが、電子証明書よ。
電子証明書とは、
この公開鍵は、確かにこの人・この組織のものです
と証明するためのデータなの。
そして、その証明書を発行する信頼された機関を認証局というわ。
電子証明書があることで、受信者は、
この公開鍵は本当に本人のものなのか?
を確認しやすくなるの。
つまり、デジタル署名だけではなく、電子証明書と組み合わせることで、より安全に本人確認ができるのよ。
デジタル署名は、いろいろな場面で使われているわ。
例えば、ソフトウェアにデジタル署名があると、
このソフトは正規の開発元が作ったものか?
配布後に改ざんされていないか?
を確認しやすくなるわ。
また、電子契約書では、
誰が署名したのか
署名後に内容が変えられていないか
を確認するために使われるのよ。
最後に、デジタル署名についてまとめるわね。
デジタル署名とは、秘密鍵でデータに署名し、公開鍵でその署名を検証することで、本人性と改ざんされていないことを確認する仕組み。
ポイントは、次の3つよ。
試験や記事では、特にこの形で覚えておくといいわ。
デジタル署名は、送信者の秘密鍵で作成し、送信者の公開鍵で検証する。
それじゃあね!


