【高校情報】3分でわかる!ハフマン圧縮とは何かわかりやすく解説

ハフマン圧縮とは??
ハフマン圧縮って聞いたことある?
これは、
よく出るデータを短く、あまり出ないデータを長く表現することで、全体のデータ量を減らす圧縮方法
よ。
普通はすべてのデータを同じ長さで表すけど、それだと無駄が多いのよね。
そこでハフマン圧縮では、出現回数(頻度)に応じてビット数を変えるの。
つまり、
- よく出る → 短いコード
- あまり出ない → 長いコード
にするのね。
ハフマン圧縮の具体例
例えば、次の文字列を見てみましょう。
aaaabbc
この文字列の出現回数は、
- a:4回
- b:2回
- c:1回
ここで重要なのは、aが一番多く、cが一番少ないという点よ。
ハフマン圧縮では、「ハフマン木」という構造を使って符号を決めるの。
ハフマン木の構築手順
- 各文字に出現回数を割り当てる
- 出現回数の少ないもの同士を結合する
- これを繰り返して1つの木にする
ここがハフマン圧縮のいちばん大事なところよ。
まず、今回の文字列 aaaabbc の出現回数を整理すると、こうなるわ。
a(4) b(2) c(1)
この中で、いちばん出現回数が少ないのは c(1)、次に少ないのは b(2) よね。
ハフマン木では、出現回数の少ないもの同士から先に結合するのがルールなの。
だから、最初にこの2つをまとめるわ。
c(1) + b(2) → (3)
これは、c と b をひとつのグループにしたという意味よ。
そして、そのグループの出現回数は、1 + 2 だから 3 になるの。
すると、今度はこうなるわね。
a(4) (3)
残ったのは、a(4) と、さっき作ったグループ (3) の2つ。
これをさらに結合すると、こうなるの。
(3) + a(4) → (7)
こうして、全部の文字を含んだ1つのまとまりができたわ。
この (7) は、文字列全体の文字数と同じで、木のいちばん上の部分になるのよ。
木の形にするとこうなる
(7)
/ \
a(4) (3)
/ \
c(1) b(2)
この図を見ると、a は上のほうにいて、b と c は下のほうにあるわよね。
ハフマン木では、上にある文字ほど短い符号、下にある文字ほど長い符号になるの。
つまり、たくさん出てくる a には短い符号を、あまり出てこない b や c には少し長い符号を割り当てられる、というわけね。
えっ、なぜ少ないものから結合するかって??
それは、出現回数の少ない文字を木の下のほうに追いやるためよ。
木の下に行くほど、割り当てられる符号は長くなるの。
でも、あまり出てこない文字なら、少し長くなっても全体への影響は小さいわよね。
逆に、よく出てくる文字に長い符号をつけてしまうと、全体のデータ量が大きくなってしまうの。
こうして木を作ることで、各文字にどんな長さの符号を割り当てればよいかが自然に決まるの。
符号の割り当て
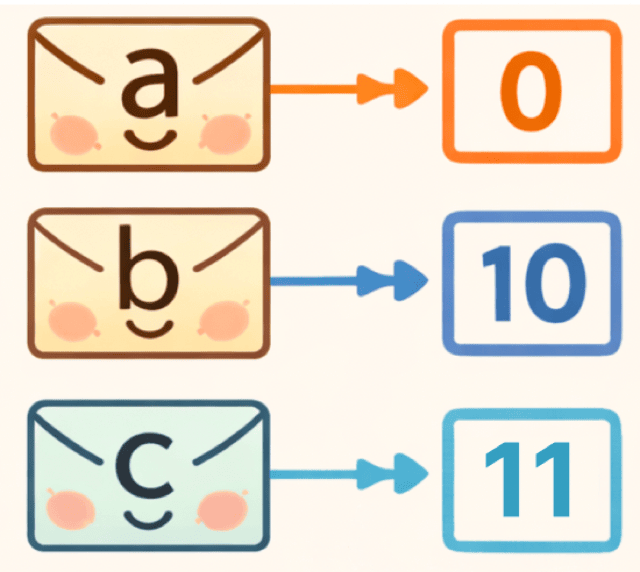
ハフマン木ができたら、次はそれぞれの文字に 0 と 1 の符号 を割り当てていくわ。
やり方はシンプルで、木を上からたどり、左に進むときは 0、右に進むときは 1 と決めるの。
今回のハフマン木はこうだったわね。
(7)
/ \
a(4) (3)
/ \
b(2) c(1)
この木を、上の頂点から各文字までたどっていくのよ。
a は、いちばん上の頂点から見て 左に1回進めばたどり着くわ。
左に進むときは 0 と決めていたから、
a = 0
になるの。
b に行くには、まず上から 右 に進み、そのあと 左 に進むわ。
右は 1、左は 0 だから、順番に並べると
b = 10
となるのよ。
c に行くには、まず上から 右 に進み、そのあともう一度 右 に進むわ。
だから、
c = 11
になるの。
こうして、それぞれの文字に対応する符号が決まるのよ。
a = 0 b = 10 c = 11
ここで注目してほしいのが、a は出現回数がいちばん多かったということよ。
そのため、木の上のほうに配置されて、結果として 短い符号 が割り当てられているの。
逆に、出現回数の少ない b や c は木の下のほうにあるので、少し長い符号になるわ。
これが、ハフマン圧縮で全体のデータ量を減らせる理由なのよ。
ここでとても大事なのが、どの符号も他の符号の先頭になっていないことなの。
これを プレフィックス条件 と呼ぶわ。
たとえば今回の符号では、
a = 0 b = 10 c = 11
0 は 10 や 11 の先頭にはなっていないし、10 も 11 の先頭にはなっていないわよね。
だから、ビット列を左から順番に読んでいけば、どこで1文字が終わるのかを迷わず判断できるのよ。
たとえば、こんな割り当てをしてしまったとするわね。
a = 0 b = 1 c = 11
このとき、ビット列 011 を読んだらどうなるかしら?
これは、
0 | 11
と読めば a, c になるし、
0 | 1 | 1
と読めば a, b, b にも見えてしまうの。
つまり、正しく元に戻せなくなるのよ。
だからハフマン圧縮では、短い符号を使いながらも、区切りがあいまいにならないようにすることがとても大切なの。
このプレフィックス条件があるおかげで、ハフマン符号は安全に復元できるのよ。
実際に圧縮してみる
それでは、実際にハフマン符号を使ってデータを圧縮してみましょう。
元の文字列はこれ ↓
aaaabbc
先ほど決めた符号はこう。
a = 0 b = 10 c = 11
このルールに従って、1文字ずつ置き換えていくのよ。
文字列「aaaabbc」を左から順に見ていきましょう。
a → 0 a → 0 a → 0 a → 0 b → 10 b → 10 c → 11
これをそのままつなげると、
0000101011
こうして、元の文字列を ビット列(0と1の並び) に変換できるの。
ここで大事なのは、よく出る文字ほど短い符号を使っているという点よ。
今回の場合、たくさん出てきた a は 1ビット(0)で表現できているわよね。
もし全部の文字を同じ長さ(たとえば2ビット)で表していたら、もっと長くなってしまうの。
つまり、出現頻度に応じて長さを変えることで、全体のデータ量を減らしているのよ。
もちろん、ちゃんと元に戻せるわ。
ビット列を左から順に読んでいけば、プレフィックス条件のおかげで、どこで1文字が終わるのかがちゃんと分かるの。
たとえば👇
0 → a 0 → a 0 → a 0 → a 10 → b 10 → b 11 → c
このようにして、元の「aaaabbc」に正しく復元できるのよ。
こうしてハフマン圧縮では、無駄を減らしながら安全にデータを扱うことができるの。
ハフマン圧縮のメリットと注意点
メリット
- データサイズを効率よく小さくできる
- 可逆圧縮なので元に戻せる
注意点
- 事前に出現頻度を調べる必要がある
- データによっては効果が小さいこともある
なぜ「ハフマン圧縮」というの?
ところで、「ハフマン圧縮」って名前、ちょっと気にならないかしら?
実はこれ、ある人物の名前がそのまま使われているのよ。
この圧縮方法を考えたのは、デビッド・A・ハフマンという人物よ。
彼は当時、大学院で情報理論を学んでいる学生だったの。

きっかけは大学の課題
ハフマン圧縮は、なんと授業の課題から生まれたの。
その課題は、
「できるだけ効率よくデータを表現する方法を考えなさい」
というものだったのよ。
最初は別の方法を考えていたんだけど、途中でより効率の良い方法に気づいたの。
それが、今まで学んできたハフマン圧縮なのよ。
なぜすごいの?
この方法がすごいのは、
出現回数に応じて最も効率の良い符号を自動で作れるところなの。
しかもこの方法はとても優れていて、
- 画像(JPEG)
- 音声(MP3)
- 圧縮ファイル(ZIPの一部)
など、今でもいろいろなところで使われているのよ。
まとめ
ハフマン圧縮は、
- 大学院生が考えた
- 授業の課題から生まれた
- 今でも使われ続けている
という、ちょっと驚きの背景を持っているの。
それじゃあね!

