
たしかに、プロトコルの層の順番ってややこしいわよね。
名前も長いし、7つもあるしで、最初は混乱しやすいポイントなの。
でも大丈夫。
今回は特別に、とっておきの覚え方を教えてあげるわ。
まずは一番つまずきやすいOSIの7層からいきましょう。
順番はこれ👇
👉 アプセトネデブ

上から順番に👇
たぶん、次の新作で出てくるモンスターよ。
さらに覚えやすくするなら👇
👉 「上は人、下は機械」と覚えると整理しやすいわ。
次はTCP/IPの4層よ。
順番はこれ👇
👉 @稲(アットイネ)

OSIよりかなりシンプルね。
TCP/IPは👇この流れで考えると一発よ。
👉 「何 → どう → どこ → どうやって」
今日は【高校情報】の重要テーマ、プロトコルについて学んでいくわ。
「なんとなく難しそう…」って思うかもしれないけど、実はすごくシンプルな考え方なの。
一緒に順番に理解していきましょうね。
プロトコルとは、
コンピュータ同士が通信するときのルール(約束)のこと
よ。
例えば、人と人が会話するときもルールがあるよね。
これと同じで、コンピュータ同士もルールがないと正しく通信できないの。
つまり、
プロトコル = コンピュータ同士の会話ルール

インターネットでは、さまざまな種類のコンピュータやOSがつながっているわよね。
それでも問題なく通信できるのは、共通のプロトコルが使われているからなの。
その代表が、
TCP/IP(ティーシーピー・アイピー)よ。
Transmission Control Protocol / Internet Protocol
の略で、それぞれ次のような意味があるわ。
このTCP/IPによって、世界中のコンピュータが同じルールで通信できるようになっているの。
TCP/IPでは、通信の処理を4つの階層(レイヤー)に分けて考えるわ。
通信の流れを役割ごとに分担して、効率よく・確実にデータをやり取りするための仕組みなの。
| 層 | 役割 | 例 |
|---|---|---|
| アプリケーション層 | サービスの提供(Web・メールなど) | HTTP, SMTP など |
| トランスポート層 | データのやり取りの管理 | TCP, UDP |
| インターネット層 | 通信相手の特定(住所) | IP |
| ネットワークインターフェース層 | 実際の通信(電気信号など) | LAN, Wi-Fi |
例えば、あなたがWebページを見ようとするときはこう。
そして、受信側ではこの流れが逆順で処理されるのよ。
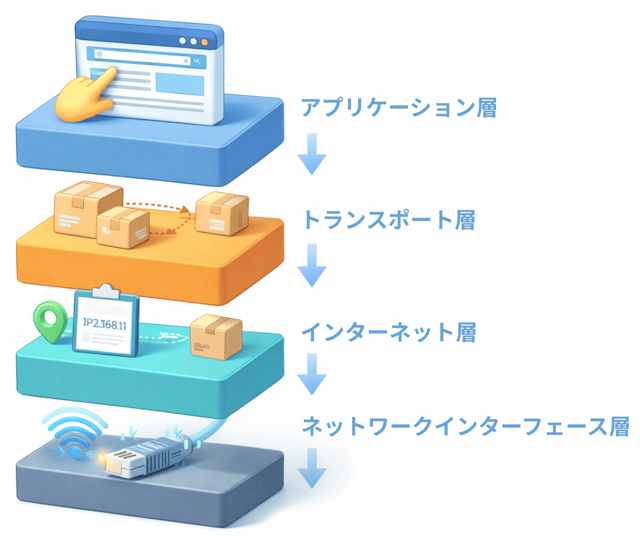
これは「荷物を送る流れ」に似ているわ。
つまり、
TCP/IPは「通信の役割分担」をすることで、インターネットを成り立たせている仕組みなのよ。
もう一つ大事なのがOSI参照モデルよ。
Open Systems Interconnection
の略で、通信の仕組みを7つの層に分けて整理したモデル(設計図)のことなの。
昔はコンピュータのメーカーごとに通信のルールが違っていて、機器同士がうまくつながらない問題があったの。
そこで登場したのが、このOSI参照モデルよ。
世界共通で通信の仕組みを理解するための基準として作られたの。
OSIの7つの層を上から順番に見ていきましょう。
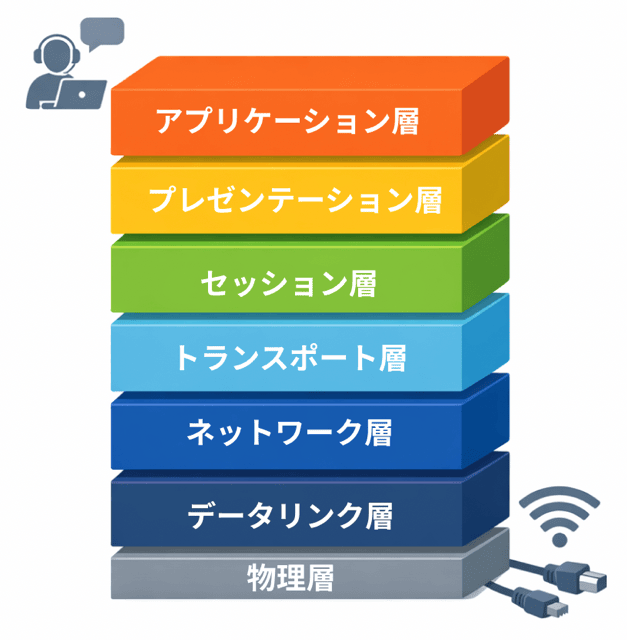
データは、送信するときに上(アプリケーション層)から下(物理層)へ流れていくの。
そして、受信側では下から上へ処理されるわ。
それぞれの層が自分の役割だけを担当することで、効率よく通信できる仕組みになっているのよ。
7つに分ける理由は以下のものがあるわ。
あとはTCP/IPとの違いも抑えておきましょう。
つまり、
OSIは「設計図」、TCP/IPは「実際に動いている仕組み」と覚えるとわかりやすいわ。
最初は7層もあって難しく感じるかもしれないけど、
「通信を細かく分担しているだけ」と考えると、一気に理解しやすくなるわよ。
ここは試験でよく出るからしっかり押さえておきましょう。
| プロトコル | 正式名称(英語) | 役割 |
|---|---|---|
| HTTP / HTTPS | HyperText Transfer Protocol / HyperText Transfer Protocol Secure | Webページを見るとき |
| SMTP | Simple Mail Transfer Protocol | メールを送るとき |
| POP / IMAP | Post Office Protocol / Internet Message Access Protocol | メールを受信するとき |
| TCP | Transmission Control Protocol | 確実にデータを届ける |
| UDP | User Datagram Protocol | 速さ重視でデータを送る |
それぞれ役割が違うので、場面によって使い分けられているの。
最後にポイントを整理しましょう。
つまり、
プロトコルがあるからこそ、世界中のコンピュータが正しく通信できるのよ。
次は「プロトコルの覚え方」を伝授するわ。
それじゃあね!
今日は集中処理システムと分散処理システムの違いについて学んでいくわ。
どちらも「コンピュータシステムの構成(処理方式)」の一種なの。
つまり、
コンピュータにどうやって処理をさせるか
が違うのね。
最初はちょっと難しく感じるかもしれないけど、一緒に順番に見ていきましょう。
コンピュータを勉強するうえで、まず知っておきたいのが集中処理システムよ。
これは、
大きなホストコンピュータに複数の端末が接続されて、すべての処理を1台のコンピュータで行う仕組み
のこと。
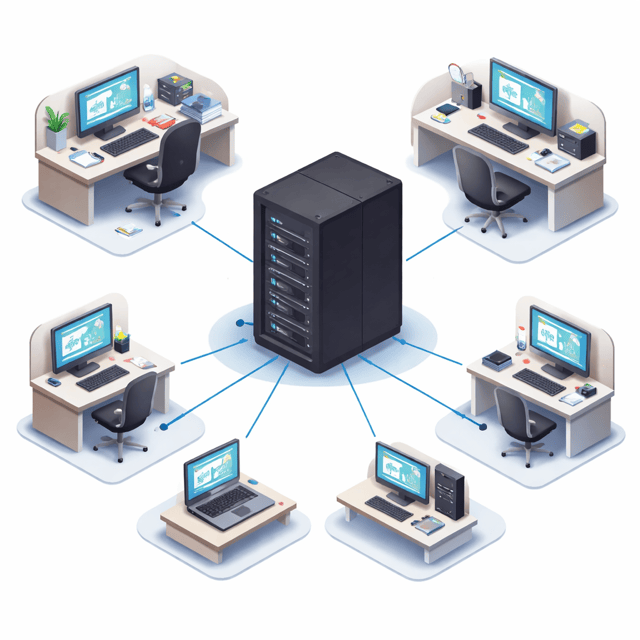
集中処理システムには以下の特徴があるわ。
イメージとしては、大きな会社で社長がすべての指示を出して、従業員がそれに従うような感じね。
それに対して分散処理システムは、
ネットワークでつながった複数のコンピュータが処理を分担して行う仕組み
よ。
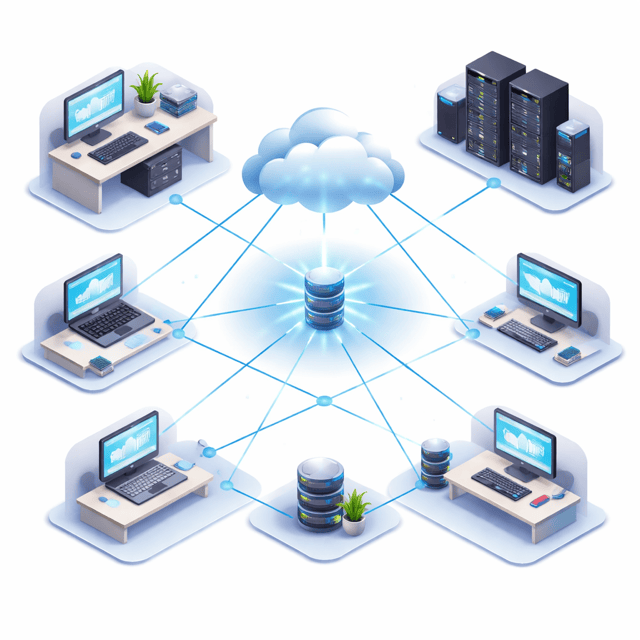
つまり、「みんなで協力して仕事をする」スタイルね。
分散処理システムには、代表的な2つの形があるわ。
クライアントサーバは、カフェで店員さんがサービスを提供してくれるイメージ。
ピアツーピアは、友達同士で助け合うようなイメージね。
| 集中処理システム | 分散処理システム |
|---|---|
| 中央集権的に管理する | 協力して処理を行う |
| すべての処理をホストが担当 | 各端末が処理を分担 |
| データを1か所で管理 | データが分散して管理される |
まとめると、
集中処理システムは「中央で全部やる」スタイル。
分散処理システムは「みんなで分担する」スタイルよ。
どちらのシステムも、使う場面によって向き・不向きがあるの。
ITの世界って、こういう選び方が大事なのよね。
ネットワークってよくわからないって言う生徒たちも多いけど、難しく考えなくて大丈夫。あたしがサクッと説明するから安心してね。
まずは、LANとWANが何を意味しているのか見ていきましょう。
LANは「ローカルエリアネットワーク(Local Area Network)」の略。
簡単に言えば、「会社や工場、学校など同一の建物や敷地内で使われるネットワーク」のことよ。
ネットワークが設置されている場所が限られているから、効率よく情報のやり取りが行われるの。
LANは通常、高速で安定しているわ。だからこそ、業務や授業などでの使用に最適なのよ。
自宅のWi-Fiなんかがいい例ね。
次にWAN。「広域ネットワーク(Wide Area Network)」ってことね。
このネットワークは「企業の支店や離れたLAN同士を結ぶ」ために使われるの。

通信事業会社の回線を用いて、広がりのあるネットワークを構築する方法よ。
代表例は、そう、インターネットよ。
さて、LANとWANの違いをもっと詳しく見ていきましょう。
まず考えるべきは、ネットワークが構築されている範囲の違いよ。
LANは、限られた範囲内での通信に特化しているから、データのやり取りが速い。
でもWANは、広範囲に渡る情報伝達を行うから、時には速度が落ちることもあるの。
次に注目するべきは、経費にかかる違いね。
LANは設置するのに費用が低いわ。
だけど、WANは遠くのLANと結ぶために高いコストがかかるのよ。
最後に、メンテナンス面についても見てみましょう。
LANは小規模だから、保守作業が楽。
反対に、WANは範囲広く見るところが多いから、メンテナンスに時間と労力が必要になるわ。
インターネットって、LANとWANがさらに繋がって世界的に発展していくものだから、今皆が使っているネットもこの二つがあってこそってことね。
それじゃあ!
ハフマン圧縮って聞いたことある?
これは、
よく出るデータを短く、あまり出ないデータを長く表現することで、全体のデータ量を減らす圧縮方法
よ。
普通はすべてのデータを同じ長さで表すけど、それだと無駄が多いのよね。
そこでハフマン圧縮では、出現回数(頻度)に応じてビット数を変えるの。
つまり、
にするのね。
例えば、次の文字列を見てみましょう。
aaaabbc
この文字列の出現回数は、
ここで重要なのは、aが一番多く、cが一番少ないという点よ。
ハフマン圧縮では、「ハフマン木」という構造を使って符号を決めるの。
ここがハフマン圧縮のいちばん大事なところよ。
まず、今回の文字列 aaaabbc の出現回数を整理すると、こうなるわ。
a(4) b(2) c(1)
この中で、いちばん出現回数が少ないのは c(1)、次に少ないのは b(2) よね。
ハフマン木では、出現回数の少ないもの同士から先に結合するのがルールなの。
だから、最初にこの2つをまとめるわ。
c(1) + b(2) → (3)
これは、c と b をひとつのグループにしたという意味よ。
そして、そのグループの出現回数は、1 + 2 だから 3 になるの。
すると、今度はこうなるわね。
a(4) (3)
残ったのは、a(4) と、さっき作ったグループ (3) の2つ。
これをさらに結合すると、こうなるの。
(3) + a(4) → (7)
こうして、全部の文字を含んだ1つのまとまりができたわ。
この (7) は、文字列全体の文字数と同じで、木のいちばん上の部分になるのよ。
(7)
/ \
a(4) (3)
/ \
c(1) b(2)
この図を見ると、a は上のほうにいて、b と c は下のほうにあるわよね。
ハフマン木では、上にある文字ほど短い符号、下にある文字ほど長い符号になるの。
つまり、たくさん出てくる a には短い符号を、あまり出てこない b や c には少し長い符号を割り当てられる、というわけね。
えっ、なぜ少ないものから結合するかって??
それは、出現回数の少ない文字を木の下のほうに追いやるためよ。
木の下に行くほど、割り当てられる符号は長くなるの。
でも、あまり出てこない文字なら、少し長くなっても全体への影響は小さいわよね。
逆に、よく出てくる文字に長い符号をつけてしまうと、全体のデータ量が大きくなってしまうの。
こうして木を作ることで、各文字にどんな長さの符号を割り当てればよいかが自然に決まるの。
ハフマン木ができたら、次はそれぞれの文字に 0 と 1 の符号 を割り当てていくわ。
やり方はシンプルで、木を上からたどり、左に進むときは 0、右に進むときは 1 と決めるの。
今回のハフマン木はこうだったわね。
(7)
/ \
a(4) (3)
/ \
b(2) c(1)
この木を、上の頂点から各文字までたどっていくのよ。
a は、いちばん上の頂点から見て 左に1回進めばたどり着くわ。
左に進むときは 0 と決めていたから、
a = 0
になるの。
b に行くには、まず上から 右 に進み、そのあと 左 に進むわ。
右は 1、左は 0 だから、順番に並べると
b = 10
となるのよ。
c に行くには、まず上から 右 に進み、そのあともう一度 右 に進むわ。
だから、
c = 11
になるの。
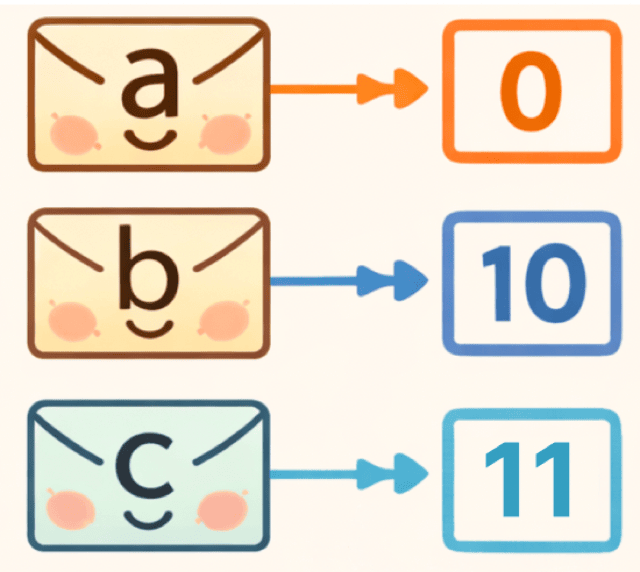
こうして、それぞれの文字に対応する符号が決まるのよ。
a = 0 b = 10 c = 11
ここで注目してほしいのが、a は出現回数がいちばん多かったということよ。
そのため、木の上のほうに配置されて、結果として 短い符号 が割り当てられているの。
逆に、出現回数の少ない b や c は木の下のほうにあるので、少し長い符号になるわ。
これが、ハフマン圧縮で全体のデータ量を減らせる理由なのよ。
ここでとても大事なのが、どの符号も他の符号の先頭になっていないことなの。
これを プレフィックス条件 と呼ぶわ。
たとえば今回の符号では、
a = 0 b = 10 c = 11
0 は 10 や 11 の先頭にはなっていないし、10 も 11 の先頭にはなっていないわよね。
だから、ビット列を左から順番に読んでいけば、どこで1文字が終わるのかを迷わず判断できるのよ。
たとえば、こんな割り当てをしてしまったとするわね。
a = 0 b = 1 c = 11
このとき、ビット列 011 を読んだらどうなるかしら?
これは、
0 | 11
と読めば a, c になるし、
0 | 1 | 1
と読めば a, b, b にも見えてしまうの。
つまり、正しく元に戻せなくなるのよ。
だからハフマン圧縮では、短い符号を使いながらも、区切りがあいまいにならないようにすることがとても大切なの。
このプレフィックス条件があるおかげで、ハフマン符号は安全に復元できるのよ。
それでは、実際にハフマン符号を使ってデータを圧縮してみましょう。
元の文字列はこれ ↓
aaaabbc
先ほど決めた符号はこう。
a = 0 b = 10 c = 11
このルールに従って、1文字ずつ置き換えていくのよ。
文字列「aaaabbc」を左から順に見ていきましょう。
a → 0 a → 0 a → 0 a → 0 b → 10 b → 10 c → 11
これをそのままつなげると、
0000101011
こうして、元の文字列を ビット列(0と1の並び) に変換できるの。
ここで大事なのは、よく出る文字ほど短い符号を使っているという点よ。
今回の場合、たくさん出てきた a は 1ビット(0)で表現できているわよね。
もし全部の文字を同じ長さ(たとえば2ビット)で表していたら、もっと長くなってしまうの。
つまり、出現頻度に応じて長さを変えることで、全体のデータ量を減らしているのよ。
もちろん、ちゃんと元に戻せるわ。
ビット列を左から順に読んでいけば、プレフィックス条件のおかげで、どこで1文字が終わるのかがちゃんと分かるの。
たとえば👇
0 → a 0 → a 0 → a 0 → a 10 → b 10 → b 11 → c
このようにして、元の「aaaabbc」に正しく復元できるのよ。
こうしてハフマン圧縮では、無駄を減らしながら安全にデータを扱うことができるの。
ところで、「ハフマン圧縮」って名前、ちょっと気にならないかしら?
実はこれ、ある人物の名前がそのまま使われているのよ。
この圧縮方法を考えたのは、デビッド・A・ハフマンという人物よ。
彼は当時、大学院で情報理論を学んでいる学生だったの。

ハフマン圧縮は、なんと授業の課題から生まれたの。
その課題は、
「できるだけ効率よくデータを表現する方法を考えなさい」
というものだったのよ。
最初は別の方法を考えていたんだけど、途中でより効率の良い方法に気づいたの。
それが、今まで学んできたハフマン圧縮なのよ。
この方法がすごいのは、
出現回数に応じて最も効率の良い符号を自動で作れるところなの。
しかもこの方法はとても優れていて、
など、今でもいろいろなところで使われているのよ。
ハフマン圧縮は、
という、ちょっと驚きの背景を持っているの。
それじゃあね!
LZ圧縮とは、
過去に出てきたデータを再利用して、データ量を減らす圧縮方法
よ。
同じデータが出てきたときに、そのままもう一度書くんじゃなくて、
「さっき出てきた場所を参照する」のがポイント。
LZ圧縮では、データを読みながら、過去に同じ並びがないか探していくの。
そして見つかったら、こんな形で表すのよ👇
$$
(何文字前,何文字分)
$$
これは、「何文字前に戻って、そこから何文字コピーするか」という意味よ。
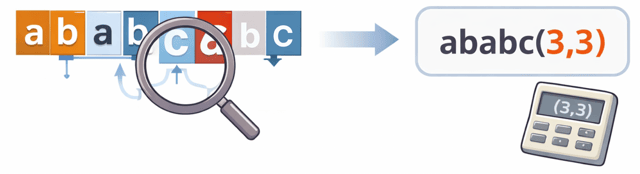
例えば、次のデータを見てみましょう。
ababcabc
あら、後に
abc
が2回続けて出てるわね。これは圧縮しないと損損。
ここで登場するのが「参照」よ。
後ろの「abc」は、前の「abc」と同じなので👇
$$
(3,3)
$$
と表せるの。
つまり、「3文字前から3文字コピー」という意味ね。
最終的にはこんなイメージになるわ👇
ababc(3,3)
この仕組みによって、データサイズをぐっと小さくできるの。
便利な技術だけど、注意点もあるわ。
ところで、「LZ圧縮」ってちょっと不思議な名前。
マンジンガーZ感、あるわよね。
えっ、
LさんとZさんが作ったの?
って思った??
鋭いわね。
実はその通りなの。
LZは、次の2人の研究者の頭文字なの。

この2人が考えた圧縮方法だから、LZ圧縮と呼ばれているのよ。
この2人は、イスラエルの計算機科学者で、1970年代にこの圧縮方法を考えたの。
つまり、LZ圧縮はイスラエル生まれの技術ということね。
ところで、どうしてLZ圧縮なんて仕組みが考えられたのか、気にならないかしら?
実はこれ、当時のコンピュータ事情が大きく関係しているの。
LZ圧縮が生まれた1970年代は、今と比べてコンピュータの性能がとても低かったの。
つまり、データをそのまま扱うのは非効率すぎたのよ。

実は、LZ圧縮が登場する前にも圧縮方法はあったのよ。
でも、それらはあらかじめ決められたルールに基づいて圧縮する必要があったの。
つまり、データの種類ごとに工夫が必要で、汎用的に使いにくいという課題があったのよ。
そこで登場したのがLZ圧縮。
この方法はなんと、
データの中から自動で繰り返しを見つけるの。
つまり、事前にルールを決めなくても、
「さっき出てきた部分を使い回す」だけで圧縮できるという仕組みなのよ。
この考え方はとても優れていて、
現在のZIPやPNGなどの圧縮技術にもつながっているのよ。
それじゃあね!また次の楽しい勉強で会いましょうね。
「ランレングス圧縮」とは、
同じデータが連続している部分をまとめて表現する圧縮方法
よ。
まずはランレングス圧縮の基本的な手順を理解しましょう。
簡単でしょ?
例えば、おなじみの画像形式の一つ、JPEGや、古いけどまだ使われているFAXなどに使われているのよ。
言葉だけじゃ分かりにくいから、具体例を見ましょう!
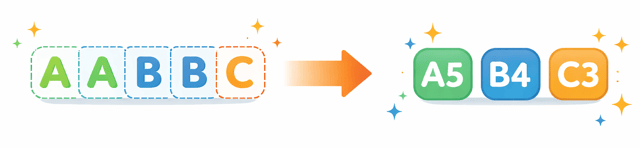
例えば、こんな文字列を考えてみて。
AAABBBCCDAA
これをランレングス圧縮するとどうなるかしら?
すると、圧縮された結果は、
A3B3C2D1A2
になるのよ。
ランレングス圧縮には当然、いい面とそうでない面があるのよ。
ね、ちょっと理解が深まったかしら。
ところでこの「ランレングス圧縮」って、ちょっと変わった名前よね。
「ラン・レングスさん」という人にちなんで名付けられたのかしら……?

それとも新しいファッションアイテムの名前かしら。
ノンノン、じつは違うのよ。
run(ラン)は「連続」、length(レングス)は「長さ」という意味よ。
つまり、ランレングス圧縮とは、
「連続しているデータの長さ」を記録する圧縮方法ということなの。
たとえば、こんなデータがあったとするわね。
AAAAA
普通ならAを5回書くけれど、ランレングス圧縮ではこうなるの。
A5
つまり、「Aが5回続いている」という長さ(length)だけを記録しているのよ。
こう考えると、「ランレングス」という名前も、とっても分かりやすいでしょ?
それじゃあね!
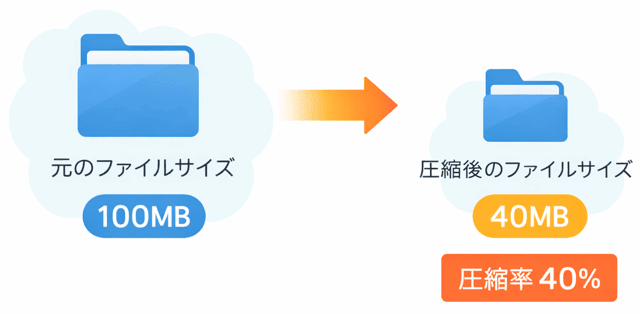
ファイルの圧縮率は、
元のファイルサイズに対して、圧縮後のファイルサイズがどれくらい残っているか
を表すものなの。
まずは基本の公式を紹介するわ。
$$
\text{圧縮率} = \frac{\text{圧縮後のファイルサイズ}}{\text{元のファイルサイズ}} \times 100
$$
早速使ってみましょう。
元のファイルサイズが100MBで、圧縮後が40MBの場合の圧縮率はいくつになるかしら。
$$
\frac{40}{100} \times 100 = 40\%
$$
つまり、圧縮率は40%になるわ。
ここが超重要!
たとえば、
ってことね。
実は、「圧縮率」という言葉は使い方が2種類あるの。
でも、試験ではこの「残った割合」の式が使われることが多いので、しっかり覚えておきましょう。
問題文をよく読んで、「残り」なのか「減少」なのかを見分けるのよ。
それじゃあね!
今日は可逆圧縮と非可逆圧縮について学んでいくわね。
皆も圧縮って言葉を聞いたことがあるかもしれないけど、その違いをちゃんと理解しているかしら?
それを3分でわかるように説明するわね。
圧縮には大きく分けて可逆圧縮と非可逆圧縮の2つがあるわ。
まず可逆圧縮について。
これは、
元のデータを完全に復元できる圧縮方法
よ。
例えば、ZIPファイルを思い浮かべてみて。

これは、データを再度展開しても元のデータが完全に復元できる典型例ね。
なので、重要なデータやソースコードでは可逆圧縮が好まれることが多いわ。
次に非可逆圧縮について説明するわ。
これは、
元のデータを完全には戻せない圧縮方法
よ。
圧縮する過程でデータの一部が失われてしまうの。それによってファイルサイズがぐっと小さくなるのよ。
音楽ファイルのMP3や動画ファイルのMP4なんかがこれにあたるわ。少しの情報を削ることで、元のデータにほぼ似た情報を再生することが可能なの。
だから、大容量のメディアコンテンツには非可逆圧縮が使われることが多いの。
具体的な例を見てみましょう。
どれも展開すると元のファイルに完全に戻せるわ。
この例の覚え方は、
ZIP・RAR・PNGは「チンしたら元に戻る」
でどう??
ジップ(ZIP)ラップ(RAR・PNG)で包んで、レンジでチンすると元に戻るイメージを思い浮かべましょう。

データが少し失われるけど、使いやすいサイズになってるの。
この例の覚え方は、
日本地図は圧縮したら元に戻らない
でどう??
ってな感じで対応しているわ。

それじゃあ、またね!
似た言葉が多くて混乱しやすいけど、ちゃんと整理すればシンプルよ。
データの情報を保ったまま、サイズを小さくすることよ。

圧縮されたデータを元の状態に戻すこと。

圧縮ファイルを開くこと。
伸張とほぼ同じ意味で使われるけど、日常的な言い方よ。
圧縮ファイルの中身を取り出して使える状態にすること。

元の状態に戻すこと全般を指す言葉よ。

圧縮データに限らず、バックアップから戻すときなどにも使われるの。
| 用語 | 意味 | イメージ |
|---|---|---|
| 圧縮 | データを小さくする | ぎゅっと詰める |
| 伸張 | 元に戻す(正式用語) | 元に戻す |
| 解凍 | 圧縮ファイルを開く | 溶かす |
| 展開 | 中身を取り出して使う | 広げる |
| 復元 | 元に戻す(広い意味) | バックアップから戻す |
ポイントは、圧縮 ↔ 伸張が正式な対語ってことかしら。
それじゃあね!
前回は「2進数の小数を10進数に戻す方法」を勉強してきたわね。
すると、
「2進数の小数ってどうやって10進数に戻すの?」
って思っちゃうわよね。
そんな疑問、今日は一気に解決するわよ。
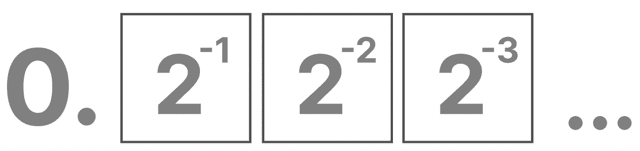
2進数の小数は、次のように計算するの。
$$
各桁 × 2^{-1}, 2^{-2}, 2^{-3}…
$$
つまり、小数点の右側は
という意味を持っているのよ。
まずは次の例題を一緒に解いてみましょう。
これは
$$
0.101_2 = 1×2^{-1} + 0×2^{-2} + 1×2^{-3}
$$
それぞれ計算すると
$$
= 0.5 + 0 + 0.125
$$
$$
= 0.625
$$
だから答えは
$$
0.625
$$
になるわ。
お次はこの問題。
$$
0.1101_2 = 1×2^{-1} + 1×2^{-2} + 0×2^{-3} + 1×2^{-4}
$$
$$
= 0.5 + 0.25 + 0 + 0.0625
$$
$$
= 0.8125
$$
さっきより違って、整数部分があるパターンね。
こういう問題は、整数部分と小数部分にわけて考えるわ。
$$
10_2 = 2
$$
$$
0.101_2 = 0.625
$$
$$
合計 = 2 + 0.625 = 2.625
$$
特に小数はマイナスの指数になるのが重要よ。
ぜひセットで覚えておいてね。
それじゃあ!
「0.3が2進数で表せないってどういうこと?」
「小数ってどうやって2進数にするの?」
そんな疑問、持っている人多いのよね。
でも安心して。
2進数の小数の計算方法の手順はたった1つなの。

2進数の小数は、次の手順で求めるわ。
これだけでOKよ。
次の問題を一緒に解いていきましょう。
では順番にやっていくわね。
まずは「0.」を確定させましょう。
今回扱う数は1未満なので、2進数でも整数部分は0ね。
そのため、最初は
0.
からスタートよ。
次は小数「0.625」を2倍。
$$0.625 \times 2 = 1.25 \quad → 1$$
整数部分は1ね。
だから、「0.」の次に続くのは「1」で
0.1
になる。
同じことを残りの小数で繰り返すわ。
1を引いた残りの小数は「0.25」。これをまた2倍しましょう。
$$
0.25 \times 2 = 0.5 \quad → 0
$$
今度は0。ってことで、
0.10
になる。
お次も同じね。1を前回は取り出さなかったから、残りは「0.5」。これを2倍すると、
$$
0.5 \times 2 = 1.0 \quad → 1
$$
うん、「1」が出てきた。
オッケー、1を取り出すと、
$$
0.101
$$
になるわ。1.0から1を取ったから、もう残りは0。
ってことで計算終了。
よって、0.625を2進数で表すと、
$$
0.101
$$
になるわ。
おっと、ここからが本番よ。
なんと、無限に続くパターンもあるの。
同じように計算してみると…
$$
0.3 \times 2 = 0.6 → 0
$$
$$
0.6 \times 2 = 1.2 → 1
$$
$$
0.2 \times 2 = 0.4 → 0
$$
$$
0.4 \times 2 = 0.8 → 0
$$
$$
0.8 \times 2 = 1.6 → 1
$$
$$
0.6 \times 2 = 1.2 → 1
$$
……
同じパターンが繰り返されて、
$$
0.0100110011…
$$
と無限に続く小数になるわ。
これはシンプルで、
2進数では割り切れない数だからよ。
10進数でも
1 ÷ 3 = 0.333333...
みたいに無限になることがあるわよね。
それと同じ現象よ。
特に順番通りに並べることは大事よ。
そうそう、そう思っちゃうわよね。
2進数の小数は、
1/2(=0.5), 1/4(=0.25), 1/8(=0.125)…
という「2の分数」の組み合わせでできてるわ。
つまり最初に知りたいのは、
「この数は 0.5(=2⁻¹)以上か?」
ということ。
2進数の小数の一番左の桁は、
2⁻¹(=0.5)の位
だから、
と判断できるわね。
ここで「2倍」が登場よ。
数を2倍すると、
0.5(=2⁻¹)が 1(=2⁰)に繰り上がる!
つまり、
0.5以上かどうかが、整数部分として現れるの。
例:0.625 × 2 = 1.25 → 「1」が出る(0.5以上)
この「1」が、2進数の最初の桁(2⁻¹の位)になるってわけね。
そのあと何をしている??
整数部分を取り除いて、残りで同じことを繰り返してるわね。
つまり毎回、
「この数は次の位(1/4, 1/8…)以上か?」
を判定しているの。
ってことで、2倍しているのは、単なる気まぐれではないわ。
「その数がどの2の位を持っているか」をチェックするため
なのよ。
ぜひ繰り返し練習して、しっかり身につけてね。
それじゃあ!
