
SSL(Secure Sockets Layer)とTLS(Transport Layer Security)はどちらも、
安全なデータ転送を実現するために使われるプロトコルの一種。
主な違いは、
TLSがSSLの改良版であり、より安全性が高い
ということね。

SSLが初めて登場したのは1994年。
データ通信を暗号化して第三者からの盗聴を防ぐためだったわ。
でも、SSLにはいくつかの脆弱性が見つかってしまい、そこで後を引き継いだのがTLSなの。
現在では、TLSが主流ね。
ブラウザやメールクライアントなどで利用されているわ。
SSLはもう時代遅れだけど、歴史的な経緯からまだその名前が使われることもあるの。
SSL/TLSがよく使われている代表例が、Webサイトの通信なの。
普段、私たちがWebページを見るときには、ブラウザとWebサーバーの間でデータのやり取りが行われているわ。
このときに使われる通信の仕組みが、HTTPやHTTPSよ。
HTTPとは、Webページのデータをやり取りするための通信ルールのことよ。
正式には、HyperText Transfer Protocolというの。
例えば、ブラウザでWebサイトを開くとき、
ブラウザ「このページを見せて!」
サーバー「はい、このページのデータです!」
というやり取りが行われているの。

このやり取りのルールがHTTPなのよ。
ただし、HTTPには大きな弱点があるわ。
それは、通信内容が暗号化されないこと。
つまり、HTTPのままだと、ブラウザとサーバーの間でやり取りされる情報が、第三者に盗み見される危険があるの。
例えば、HTTPのページでログインIDやパスワードを入力した場合、その情報が暗号化されずに送られてしまう可能性があるわ。
もちろん、実際のネットワークではいろいろな仕組みが関係するけれど、イメージとしては、
はがきにパスワードを書いて送る
ようなものね。
はがきは、途中で誰かに見られる可能性があるでしょう?
HTTPもそれに近いイメージなの。
そこで使われるのが、HTTPSよ。
HTTPSは、
HTTPにSSL/TLSによる暗号化を加えた通信方式
なの。
つまり、
HTTPS = HTTP + SSL/TLSによる暗号化
と考えると分かりやすいわ。

HTTPSでは、ブラウザとWebサーバーの間の通信がSSL/TLSによって暗号化されるの。
そのため、ログインID、パスワード、お問い合わせフォームの内容、クレジットカード情報などを、第三者に盗み見されにくくできるわ。
URLを見ると、HTTPとHTTPSの違いはすぐに分かるの。
HTTPのWebサイトは、
http://example.com
のように、http://で始まるわ。
一方、HTTPSのWebサイトは、
https://example.com
のように、https://で始まるの。
この「S」は、SecureのSよ。
つまり、HTTPSは「安全性を高めたHTTP」と考えればいいわね。
| 項目 | HTTP | HTTPS |
|---|---|---|
| 通信の暗号化 | されない | される |
| URL | http:// で始まる | https:// で始まる |
| 安全性 | 通信内容を盗み見される可能性がある | 通信内容を盗み見されにくい |
| 使われる技術 | HTTP | HTTP + SSL/TLS |
昔は、単なる情報ページならHTTPでも使われることが多かったの。
でも現在では、ログインや決済があるページだけでなく、ほとんどのWebサイトでHTTPSが使われるようになっているわ。
なぜなら、Webサイトの安全性を高めるだけでなく、利用者に安心感を与えることにもつながるからよ。
SSL/TLSは単体で目に見えるものではないけれど、私たちが安全にWebサイトを利用するために、HTTPSの裏側でしっかり働いているの。
じゃ、今日はここまで。
またブログで会いましょう!
近頃、インターネットでのデータのやり取りにおいて、暗号化技術の進展が重要な役割を果たしているのを知ってる?
これがあるから大切な個人情報やクレジットカード番号を安心して送れるのよ。
まずは、暗号化方式の2種類について基本を押さえましょう。
共通鍵暗号方式は、一つの鍵でデータを暗号化と復号する方式よ。
つまり、送信者と受信者が同じ鍵を使うの。
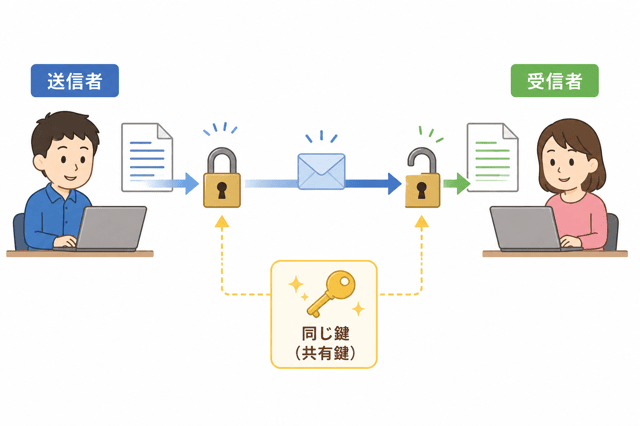
たとえば、シーザー暗号を思い出してみて。
「3文字後にずらす」を鍵として、平文「ANGOU」を暗号化すると、「DQJRX」になるわ。
受信者は共通鍵でその暗号文「DQJRX」を復号して元に戻すのよ。
問題点として、共通鍵を送る過程で第三者に盗まれると、暗号文を不正に復号されるリスクが高いのが弱点ね。
一方で、公開鍵暗号方式は2つの異なる鍵を使用するの。
ここでは、公開される鍵と秘密鍵の2つがあるの。
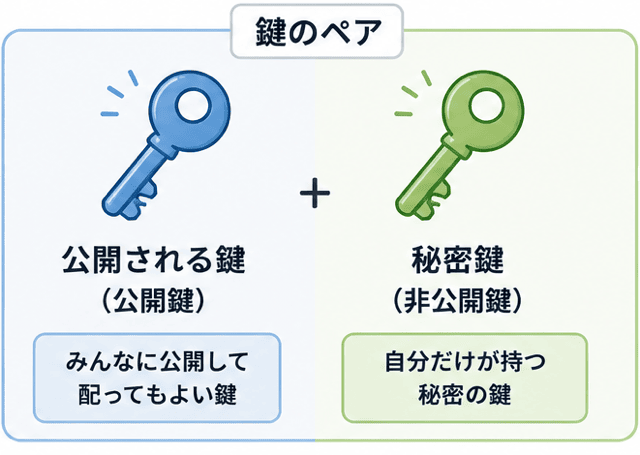
公開鍵で暗号化されたデータは、秘密鍵でしか復号できないわ。
秘密鍵は受信者だけが持っているから、安心よね。
この方式のおかげで、不特定多数とデータを交換するときに便利なの。公開鍵を配っても安全にデータのやり取りが進められるのがポイントね。
えっ。共通鍵暗号方式と公開鍵暗号方式がごちゃ混ぜになっちゃうですって??
共通暗号方式を家の鍵、公開鍵暗号方式を郵便ポストの鍵と考えるといいわよ。

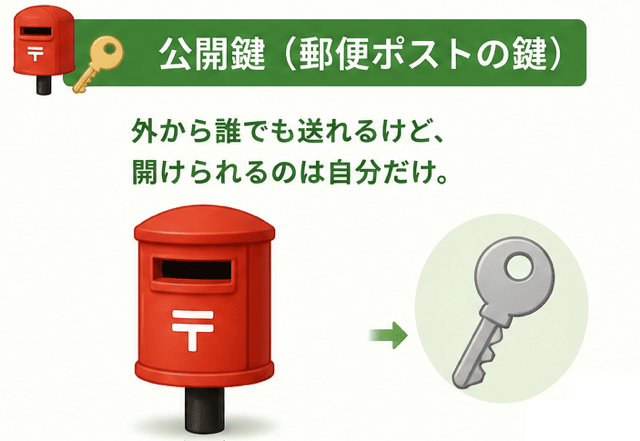
このイメージで整理すれば、もう暗号方式の違いに迷うことはないわ。
どんなデータを守りたいか、そしてどんな状況で使うのかを思い浮かべると役立つはず。
データの送受信中にノイズなんかで誤りが起こることって、あるの。
それが原因で送ったデータと受け取ったデータが変わっちゃったら大変よ。
そこで使われるのが誤り検出符号やパリティビットってわけ。
誤り検出符号とはズバリ、
データ送信時に誤りが起きたか検出するための仕組み
よ。

データに少しだけ情報を付け加えることで、間違いが起こったかどうかをチェックできるの。
たとえば、インターネット通信やWi-Fi通信では、途中でノイズの影響を受けることがあるの。
本来、
1011001
と送ったはずなのに、
1010001
のように、一部が変わってしまうこともあるわ。
そんな通信ミスを見つけるために使われるのが誤り検出符号よ。
送るデータに、確認用の追加情報をくっつけて送信するの。
受け取った側は、その追加情報と元データを照らし合わせて、
と判断するのよ。
見えないところで、私たちの生活をかなり支えている技術なのよ。
さて、そんな誤り検出符号の中でもっとも有名なのがパリティビットよ。
これは、
データ中の「1」の数が偶数(または奇数)になるように、1ビット追加する方法
なの。
もし受信後に数が合わなければ、どこかで誤りが起きたと分かるのね。
たとえば、次のデータがあるとするわ。
1011001
この中の「1」の数を数えると、4個あるわね。
4は偶数だから、偶数パリティなら追加するビットは「0」になるの。
つまり送信するデータは、
10110010
になるのよ。
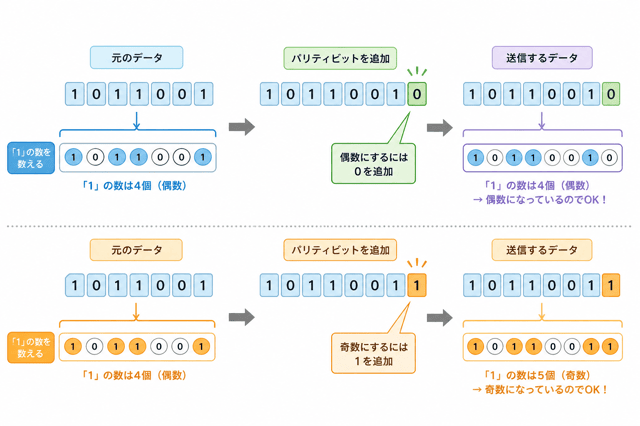
たとえば通信途中で1つの数字が変わって、
10100010
で届いたとするわ。
この場合、「1」の数は3個になってしまうの。
本来は偶数のはずなのに奇数になっているから、
どこかで誤りが起きた!
と分かるのよ。
パリティビットには2種類あるわ。
どちらを使うかは通信ルールによって決まるの。
昔から広く使われてきた理由は、この手軽さにあるのよ。
ただし、万能ではないわ。
だから、より高い信頼性が必要な場面では、CRCなど別の方式も使われるの。
パリティビットはシンプルで便利なんだけど、1ビット分しかチェックできないから、2ビット以上の反転には対応できないの。再送要求なんかもあるから注意がいるわ。
ここで少し混乱しやすいのが、誤り検出符号とパリティビットの違いよ。
結論からいうと、
パリティビットは、誤り検出符号の一種
なの。
つまり、
という関係になるわ。
りんごはフルーツだけれど、フルーツ全部がりんごではないわよね。

それと同じで、
パリティビットは誤り検出符号だけれど、誤り検出符号すべてがパリティビットではない
ということなの。
パリティビット以外にも、誤り検出符号には次のようなものがあるわ。
つまり、パリティビットは入門編として有名な代表選手というイメージでOKよ。
それじゃあね!
VPNとは、
Virtual Private Network(仮想的な専用回線)
の略で、
インターネット上に、専用の安全な通信トンネルを作る技術
よ。

つまり、普通のインターネット回線を使いながら、まるで自分専用の回線のように安全に通信できる仕組みなの。
たとえば、カフェやホテルの無料Wi-Fiを使う場面を想像してみて。

誰でも利用できるネットワークでは、通信内容を盗み見られる危険がゼロではないの。
そんなときVPNを使えば、通信内容を暗号化して守ることができるわ。
VPNは、あなたのスマホやパソコンとVPNサーバーの間に、暗号化された通信経路を作るの。
そのため、フリーWi-Fiなどでも比較的安全に通信できるというわけよ。
VPNを使えば何でも安全、というわけではないの。
つまり、VPNは安全性を高める便利な道具と考えると分かりやすいわ。
それじゃあね!
ブロックチェーンって何?
って、まず思うわよね。
難しいことばばっかりで取っつきにくいけど、一緒に学んでいきましょ。
ブロックチェーンとは、簡単に言うと
取引データなどの記録を、ブロック単位で鎖のようにつなげて管理する仕組み
なのよ。
取引履歴が記録されてる通帳みたいなものなの。
じつはブロックチェーンは分散型台帳の一種なの。
これは、
取引履歴を分散・共有して監視し合う仕組みのこと。
中央にサーバを立てなくても取引データを正しく管理できて、管理コストが低いのよ。
ブロックチェーンは、「ブロック」という取引履歴を記録したものが数珠つなぎに連なっているの。

これがチェーンの名前の由来ね。
ブロックが繋がることで、安全で改ざんされにくいデータ管理が行えるのよ。
それじゃ、この技術は他にどんな可能性があるのかしら?
この分散型の仕組みが、ゲームやデジタルコンテンツにも応用され始めているの。インターネットでの取引がより安全になるのも、その新しい可能性の一つね。
だから、将来的にはもっと多くの分野で広がっていくかもしれないわ。
でもね、ブロックチェーンはまだ新しい技術だから、法整備が不十分なのも事実なのよ。
法整備が進むことで、もっと安心して使えるようになるといいわね。
それじゃあね!
皆さん、ネットで見つけた素敵な画像をついついダウンロードしちゃったこと、あるんじゃない?
ネット上のデータは気軽にコピーされやすいから、心配なのは著作権の侵害よね。
そして、ここで登場するのが電子すかしなんだってわけ。
どうやってこの電子すかしが私たちを守っているか、わかりやすく解説していくから、しっかり聞いてね。
ズバリ
画像・動画・音声・文書などのデジタルデータに、目立たない形で情報を埋め込む技術
よ。
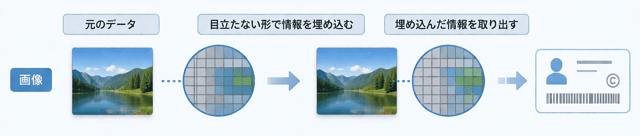
特に画像ファイルでよく使われる技術ね。
著作者の情報や著作権に関する情報を画像データに埋め込んでおくものなの。
まず、どうして電子すかしが必要なのか考えてみましょう。

例えば、あなたが自分で撮った写真をインターネットにアップしたとするわね。
まさか自分が撮った写真を無断で使われるなんて、想像しただけでも嫌よね。
だからこそ電子すかしが役立つの。
電子すかしの仕組みはとてもおもしろいの。画像ファイルに著作者名などのすかし情報を埋め込むのよ。
これをすると、不正にコピーされた場合でも、そのコピーされた画像にはすかし情報が残ったまま。
だから、著作権侵害があったことを簡単に証明できるわけ。
では、実際にどのような場面で使われているのか見てみましょう。
このように、誰が作ったのか、どこから流出したのかを追跡するために活用されているの。
電子すかしには、大きく分けて2種類あるわ。
つまり、デジタル作品を守るための心強い仕組みというわけね。
便利な電子すかしだけれど、弱点もあるのよ。
たとえば、画像を何度も圧縮したり、サイズ変更したりすると、埋め込んだ情報が弱くなることがあるの。
また、専門知識を持つ相手なら、電子すかしを消そうと試みる場合もあるわ。
だからこそ他の対策と組み合わせるのが大事。
電子すかしだけに頼るのではなく、
などと組み合わせることで、より強い著作権保護や情報管理ができるのよ。
それじゃあね!
インターネットには有益な情報もあれば、有害な情報もたくさんあるわ。特に誹謗中傷や暴力など、見たくないものもあるわよね。
そこで、これらの有害情報をフィルタリングすることで対処できるの。
それを効率的にやる方法がブラックリスト方式とホワイトリスト方式なのよ。
どちらも、フィルタリングを活用して情報の選別を行う方式の一種ね。
でも、
アプローチ方法が異なる
のよ。
ブラックリスト方式では、不適切な WebページやIPアドレスをリスト化し、それらの閲覧を制限するわ。
現実世界でのイメージで言うと、
出禁リストに載ってる人だけ入れない
って感じね。

メリットは、有害な情報を見つけ次第、リストに追加するだけで効率的にフィルタリングできるところ。
デメリットは、リストにない有害情報を見落としてしまう可能性があること。
具体例としては、子どものインターネット利用を管理する親が、ブラックリストに有害サイトを入れることで見せないようにする場合があるわ。
こちらは、有益だと判定されたWebページのみをリスト化して制限するの。
だから、リストにないサイトは一切見られない。
現実世界でのイメージで言うと、
招待客名簿にある人だけ入れる
って感じ。

メリットは、予期しない有害情報を一切シャットアウトできるところね。
デメリットは、新しく有益なサイトもリストに追加されない限り見られないこと。
セキュリティが特に重要な企業などで使用されることが多く、限られたサイトだけを表示させるのに適しているわ。
どちらのフィルタリング方法も特有のメリットとデメリットがあるわ。
どちらを選ぶかは目的に応じた判断が重要よ。
言葉だけだと少し分かりにくいかもしれないわね。
ここでは、身近な例でイメージしてみましょう。
たとえば、メールサービスで迷惑メール対策をするとき、
このように、危険だと分かった相手だけをブロックするのがブラックリスト方式よ。
一方で、会社のパソコンや学校の端末では、
このように、安全と確認されたものだけ許可するのがホワイトリスト方式よ。
一般家庭のネット利用では、使いやすいブラックリスト方式が多いわ。
逆に、企業の重要システムや金融機関では、安全性を重視してホワイトリスト方式がよく使われるの。
つまり、
利便性ならブラックリスト方式
安全性ならホワイトリスト方式
と覚えておくと分かりやすいわ。
最後に、ブラックリスト方式とホワイトリスト方式の違いを整理しておきましょう。
| 項目 | ブラックリスト方式 | ホワイトリスト方式 |
|---|---|---|
| 考え方 | 危険なものだけ拒否する | 安全なものだけ許可する |
| 安全性 | やや低い | 非常に高い |
| 使いやすさ | 高い | やや低い |
| 管理の手間 | 少ない | 多い |
| 向いている場面 | 家庭・一般利用 | 企業・金融機関・重要設備 |
それじゃあね!
さてさて、コンピュータを使うとき、ちょっとした不安を感じたことはない?
ほら、突然重くなったり、不審なメッセージが出てきたりして……。
そういうときに役立つのがファイアウォールなんだよね。
まずはファイアウォールについて見ていきましょう。
ファイアウォールとは、
ネットワークへの不正アクセスや危険な通信を防ぐ仕組み
よ。
不正なアクセスを阻止するために作られた守護神みたいなものなのね。

ネットワークに入ってくるデータと、出て行くデータのチェックを行ってくれるの。
つまり、悪意ある攻撃やウイルスから守ってくれる盾とも言えるわね。
ネットワーク型とホスト型のファイアウォールがあるんだけど、これも重要なポイントよ。
ネットワーク型は、大規模な環境で使われることが多く、ホスト型は個別のPCにインストールするタイプなの。
次に、セキュリティホールとは、
コンピュータやソフトウェアにある安全上の欠陥・弱点 のこと
ね。
いわばソフトウェアやシステムに生まれちゃった「穴」みたいなものなのよ。

バグや設計のミスによって、潜在的に悪用される危険があるのがセキュリティホール。
これが見つかると、ハッカーたちはそこから侵入を企んでくるの。
セキュリティホール対策としては、OSやアプリケーションのアップデートを忘れずに行うこと。
そして、ウイルス対策ソフトをしっかり使うことがポイントよ。
さて、いよいよ今日の本題ね。
ファイアウォールとセキュリティホールの違い??
もう、この2つは360度ぐらい異なっちゃってるわ。違いというか、もう正反対。
攻めと守りの関係になってるの!
ファイアウォールはネットワークやPCを守る!
それに対して、セキュリティホールはシステムの弱点を突いてくるものよ。
えっ、サッカーに例えるなら??
そうね。
ファイアウォールはゴールキーパー、セキュリティホールはエースストライカーよ。

さあ、キックオフよ!
それじゃ、お互いの役割を忘れずに、安心してインターネットを楽しんでちょうだい!
コンピューターウイルスとマルウェアの違い??
すばりいっちゃうとね、
用語の示す範囲が違うの。
マルウェアの方が範囲が広くて、ウイルスはじつはマルウェアの一部。
ちょっとかっこよくいうと、
包含関係にある(ウイルスはマルウェアに含まれる)ってわけよ。
じゃあ、この違いをもうちょっと詳しく見てみるわよ。
マルウェアとは、
悪意のあるソフトウェアの総称
よ。

mal(悪意ある) + software(プログラム)
を組み合わせた言葉なの。
つまり、悪意を持ったプログラム全般を指しているのね。
この中には、ウイルスの他にも、ワームやトロイの木馬なんかも含まれているのよ。
コンピューターウイルスとは、
自分で増殖し、他のプログラムに感染するマルウェア
よ。

ウイルスは他のファイルやシステムに寄生や感染する特徴を持っているわ。
感染したら、自分のコピーを広めたり、システムを破壊したりする特性があるの。
どう??
コンピューターウイルスとマルウェアの違いしっくりきたかしら。
おさらいすると、
包含関係にある(ウイルスはマルウェアに含まれる)ってわけよ。
つまり、
コンピューターウイルスはマルウェアなんだけど、マルウェアはコンピューターウイルスじゃないのね。
この関係は・・・そう。
文房具と鉛筆の関係ね。

鉛筆は文房具の一種。鉛筆は文房具だけど、鉛筆は文房具じゃないでしょ?
それと一緒よ。
マルウェアが文房具だとしたら、コンピューターウイルスは鉛筆ね。
ただし、普通の鉛筆じゃないわ。
「勝手に増える鉛筆」みたいな存在なの。

これだけは頭に入れておきましょう。
リレーショナルデータベースとはズバリ、
表(テーブル)同士を関係(リレーション)でつなげたデータベース
よ。
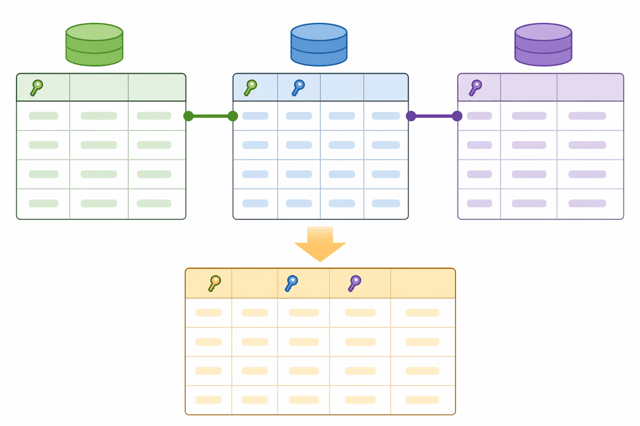
リレーショナルデータベースはいくつかのテーブル(表)で構成されているの。
それぞれのテーブルにはレコード(行)とフィールド(列)があるわ。
各レコードがデータの単位で、フィールドはそのデータの属性なのよ。
テーブルはこう考えてみて。
例えば、書籍データを管理するテーブルがあったとするわ。
| ISBN | 書籍名 | 著者コード | 分類コード |
|---|---|---|---|
| 978-4-00-33△△―△△-6 | 学問のすヽめ | JP015 | 370 |
| 978-4-90-36△△―△△-7 | 舞姫 | JP821 | 910 |
このテーブルね、行がレコード、列がフィールドなの。
ISBN、書籍名、著者コード、分類コードがそれぞれのフィールドになっているわ。
例えば、著者の情報を別のテーブルで管理するとこうなるわ。
| 著者コード | 著者名 |
|---|---|
| JP015 | 福沢諭吉 |
| JP821 | 森鴎外 |
このテーブルでは、著者コードを使って著者の情報を管理しているの。
さっきの書籍テーブルを思い出してみて。
| ISBN | 書籍名 | 著者コード | 分類コード |
|---|---|---|---|
| 978-4-00-33△△―△△-6 | 学問のすヽめ | JP015 | 370 |
| 978-4-90-36△△―△△-7 | 舞姫 | JP821 | 910 |
書籍テーブルに「著者コード」があったわよね。
で、著者テーブルにも「著者コード」がある。
| 著者コード | 著者名 |
|---|---|
| JP015 | 福沢諭吉 |
| JP821 | 森鴎外 |
この共通の項目でテーブル同士がつながるの。
つまり、
書籍テーブル + 著者テーブル
で、 「どの本の著者が誰か」がわかるってわけよ。
次に、具体的なデータ操作を見ていきましょう。
リレーショナルデータベースでは、以下の3つの操作が基本よ。
結合は、複数のテーブルを共通する項目で関連付けることなの。
これによって、一つの表としてデータを表示できるのよ。
例えば、書籍名と著者名が別のテーブルにあっても、著者コードで結合すれば一目でわかるの。
選択は、条件に合う行を取り出して表示する操作よ。
例えば、文学に関する書籍だけを見たいときに使えるわ。
文学に関連するレコードだけを選んで表示するのね。
射影により、テーブルの一部の列を抽出して新しい表を作成できるの。
例えば、ISBNと書籍名だけを見たいなら、この操作を使うわ。
まずは、さっきの2つのテーブルを確認するわ。
| ISBN | 書籍名 | 著者コード | 分類コード |
|---|---|---|---|
| 978-4-00-33△△―△△-6 | 学問のすヽめ | JP015 | 370 |
| 978-4-90-36△△―△△-7 | 舞姫 | JP821 | 910 |
| 著者コード | 著者名 |
|---|---|
| JP015 | 福沢諭吉 |
| JP821 | 森鴎外 |
著者コードで2つのテーブルを結合すると、
| 書籍名 | 著者名 |
|---|---|
| 学問のすヽめ | 福沢諭吉 |
| 舞姫 | 森鴎外 |
バラバラだった情報が1つにまとまる(結合の例)。
例えば、分類コードが「910(文学)」のものだけ選ぶと、
| ISBN | 書籍名 | 著者コード | 分類コード |
|---|---|---|---|
| 978-4-90-36△△―△△-7 | 舞姫 | JP821 | 910 |
条件に合う行だけ取り出せる(選択の例)。
書籍テーブルから「書籍名」だけ取り出すと、
| 書籍名 |
|---|
| 学問のすヽめ |
| 舞姫 |
必要な列だけ取り出せるってわけ(射影の例)。
実際のリレーショナルデータベースでは、結合・選択・射影といった操作を、SQLなどのデータ操作言語を使って行うのよ。
仮想表(ビュー)も重要よ。
仮想表とは、
実際には保存されていない「見せかけの表」
のこと。
リレーショナルデータベースではここまでみてきたように、
色々こねくり回すわね?
すると、その結果として新しい表っぽいものができるわ。
これらの操作で生成された表は、仮想的に定義されるの。
仮想表として扱うことで、セキュリティを考慮しつつデータを簡潔にまとめて利用できるのよ。
例えば、「書籍テーブル」と「著者テーブル」を結合するとこうなる。
| ISBN | 書籍名 | 著者名 | 分類コード |
|---|---|---|---|
| 978-4-00-33△△―△△-6 | 学問のすヽめ | 福沢諭吉 | 370 |
| 978-4-90-36△△―△△-7 | 舞姫 | 森鴎外 | 910 |
この表は、もともと存在していたテーブルではない新しいものよね?
結合によってその場で作られた表、これが仮想表よ。
みんな「ビッグデータ」と「オープンデータ」の違いってあまり意識したことないんじゃないかしら。
その違いを3分でスッキリしちゃいましょう。
ビッグデータとは、
大量かつ多様で高速なデータ
よ。

データのボリュームだけじゃなくて、整理や分析が容易でない複雑さも含まれるわ。
主な特徴は「3V」で表されるの。
その3Vっていうのは次のものよ。
例えば、
なんかはビッグデータのいい例ね。つまりは
日常のあらゆる行動データ
わけよ。
オープンデータとは、
一般公開されてて、誰でも利用や再配布ができるデータ
よ。

デジタルの情報を社会的に有意義で多様な方法で使うために、再利用が許可されているものなの。
オープンデータの具体例は以下のようなものよ。
つまりは、
国や自治体が公開しているデータ
ってことね。
さて、ここまででビッグデータとオープンデータについて理解が深まってれば嬉しいわ。最後にその違いを分かりやすくまとめてみましょう。
この2つの違いはズバリ、
目的と特性が異なる
という点ね。次の表を参考にするといいわ。
| 概念 | 特徴 |
|---|---|
| ビッグデータ | 大量、高速、多様なデータ群。解析が中心 |
| オープンデータ | 誰でも使用可能なデータ。公開と再利用が中心 |
それじゃあね!
データベースとは、
情報を整理して蓄えているシステムのこと
よ。つまり、
データそのものの集まりね。
スーパーの倉庫を思い浮かべてみて。

商品の種類ごとにきれいに並べられているわ。
データベースは情報をきちんと保存し、必要な時に簡単に取り出せるようにしているの。
スーパーの倉庫でも、商品がラベルなどで管理されていると探しやすいでしょ?それと同じ!
DBMSは、
Database Management System
の略よ。直訳で
データベースを管理するシステム。
つまり、データベースを扱うためのソフトウェアってことね。
簡単にいえば、
データを追加したり、更新したり、取り出したり、削除したりするためのツールよ。
スーパーでいえば、「商品を倉庫に運ぶ作業員」みたいなものね。

さあ、いよいよデータベースとDBMSの違いを見ていきましょう。
違いはズバリ、
「中身」と「それを扱う道具」
よ。
データベースがデータそのもので、DBMSはそれを操作する仕組みだからね。
もう一度イメージをおさらい。
データベースがスーパーの倉庫そのもの。
一方、DBMSはその倉庫を管理し、商品を出し入れするスタッフみたいな存在ね。
これでデータベースとDBMSの関係がはっきりしたわね。
データベースは、情報が入った箱のようなもの。
DBMSは、その箱を管理するツール。
役割が違うからこそ、お互いに協力しながら働いているの。
それじゃあね!